#LightBites")




")

Protein language models (pLMs), trained on protein sequence databases, aim to capture the fitness landscape for property prediction and design tasks. While scaling these models has become common, it assumes that the source databases accurately reflect the fitness landscape, which may not be true. Understanding protein function was historically tied to predicting structure based on physical models. However, as machine learning techniques evolved, they have proven more effective in modeling dynamic protein behaviors. By treating protein sequences like natural language, pLMs can capture structural insights without relying solely on structure databases, revealing deeper functional relationships.
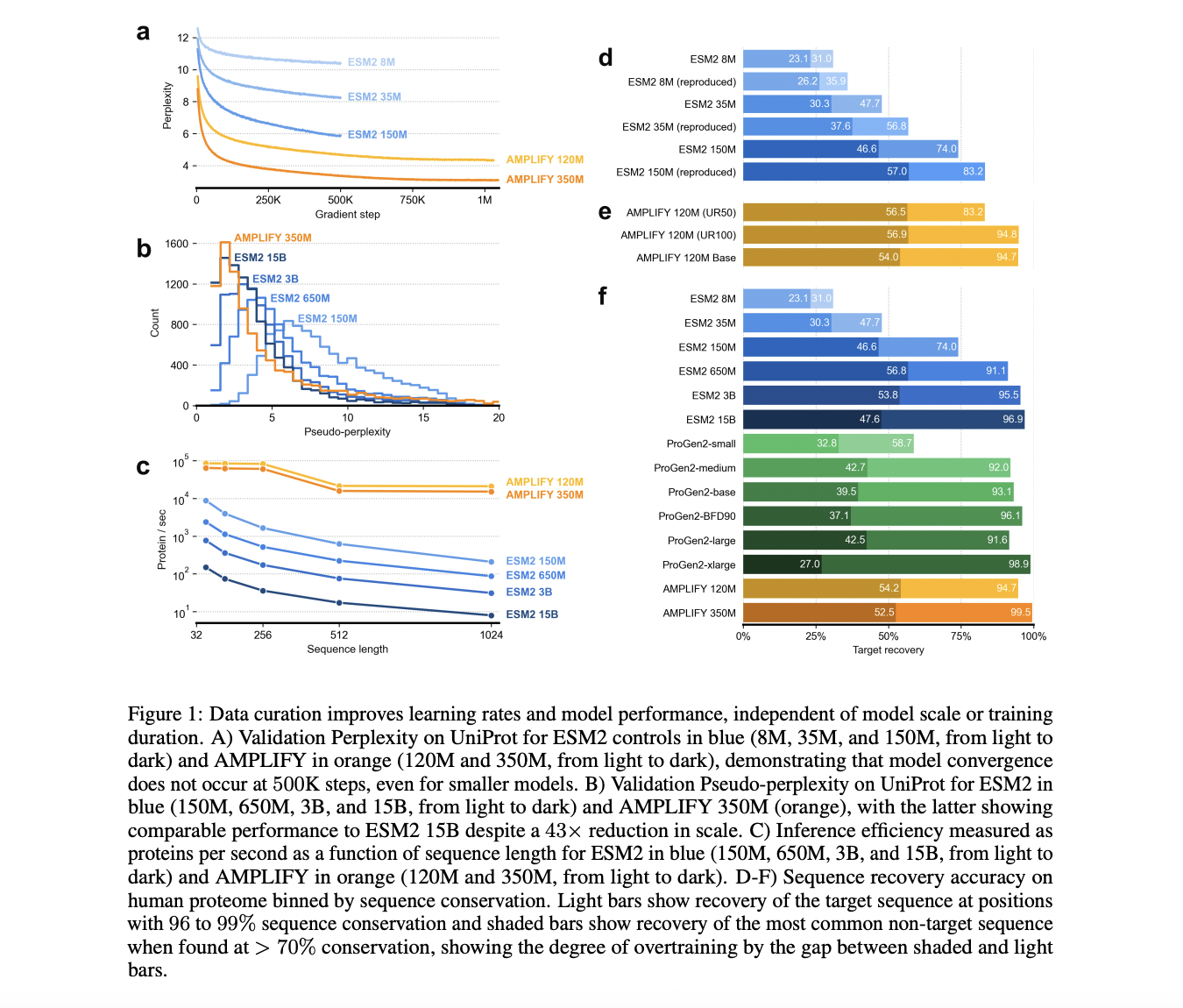
Researchers from Chandar Lab, Mila, and Amgen developed AMPLIFY, an efficient pLM that significantly reduces the cost of training and deployment compared to previous models. Unlike large-scale models like ESM2 and ProGen2, AMPLIFY focuses on improving data quality rather than model size, achieving superior performance with 43 times fewer parameters. The team evaluated three strategies—data quality, quantity, and training steps—finding that improving data quality alone can create state-of-the-art models. AMPLIFY has been open-sourced, including its codebase, data, and models, to make pLM development more accessible.
The validation data sequence sets for the pLM were created by combining reference proteome sequences with sequences from the Observed Antibody Space (OAS) and the Structural Classification of Proteins (SCOP) database. The aim was to enable task-specific validation, particularly for complementarity-determining regions of antibody sequences and sequence-to-structure tasks. High-quality reference proteomes were selected based on their BUSCO completeness scores, ensuring representation across Bacteria, Archaea, and Eukarya. Sequences lacking experimental validation or containing non-canonical amino acids were excluded. The final validation sets included 10,000 randomly selected sequences from each source after clustering to reduce redundancy.
For training data, the UniRef, OAS, SCOP, and UniProt databases were processed to remove sequences with ambiguous amino acids and those similar to validation set sequences. The training dataset specifically utilized paired heavy and light chain antibody sequences formatted with a chain break token. The AMPLIFY model architecture incorporated recent improvements from large language models in natural language processing, including a SwiGLU activation function and a memory-efficient attention mechanism. The optimization process involved enhanced AdamW and a cosine annealing scheduler, with training conducted at lower precision using advanced techniques like DeepSpeed. The vocabulary was streamlined to accommodate better multi-chain proteins, and sequences longer than 512 residues were truncated during training to improve efficiency. After initial training, the context length was expanded to 2048 residues, followed by additional training steps for both AMPLIFY models.
The study compared the impact of adjusting pLM size with factors like training dataset content, size, and duration. The authors improved their validation dataset by using sequences from UniRef100, antibody pairs from OAS, and SCOP domains, aiming for a more representative sample. They found that data curation significantly enhances model performance, independent of model size or training duration. Contrary to previous findings, they observed that performance improved beyond 500K updates, suggesting that using diverse training data is crucial. Additionally, larger models risk overfitting, indicating the need for regular retraining to adapt to evolving data quality and quantity.
Recent advancements in ML have focused on scaling neural networks, particularly in language models for text and proteins. This trend has made training state-of-the-art models prohibitively expensive for many researchers, often leading to restricted access. However, this study suggests that expertise from protein scientists can enhance the curation process, yielding competitive performance without the need for a massive scale. Effective curation relies on a community-wide understanding of proteins, which remains limited. The study emphasizes the importance of collaborative expertise and advocates for open-source methods to facilitate iterative data curation and model development, ultimately aiding therapeutic advancements.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 52k+ ML SubReddit.
We are inviting startups, companies, and research institutions who are working on small language models to participate in this upcoming ‘Small Language Models’ Magazine/Report by Marketchpost.com. This Magazine/Report will be released in late October/early November 2024. Click here to set up a call!
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.