#LightBites")




")

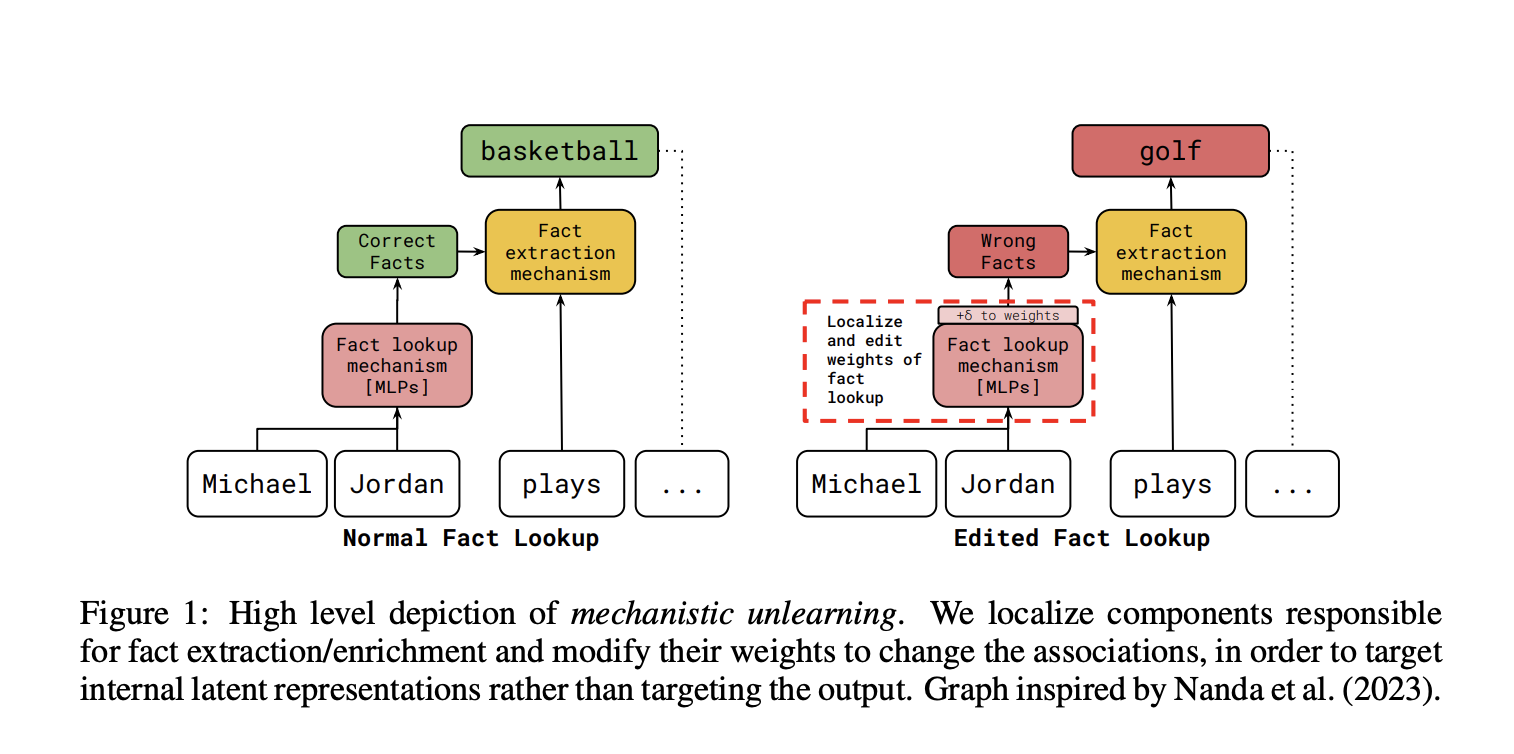
Large language models (LLMs) sometimes learn the things that we don’t want them to learn and understand knowledge. It’s important to find ways to remove or adjust this knowledge to keep AI accurate, precise, and in control. However, editing or “unlearning” specific knowledge in these models is very tough. The usual methods to do this often end up affecting other information or general information in the model, which can affect its overall abilities. Additionally, the changes made may not always last.
In recent works, researchers have used methods like causal tracing to locate key components for output generation, while faster techniques like attribution patching help pinpoint important parts more quickly. Editing and unlearning methods try to remove or change certain information in a model to keep it safe and fair. But sometimes, models can learn back or show unwanted information. Current methods for knowledge editing and unlearning often affect other capabilities of the model and lack robustness, as slight variations in prompts can still elicit the original knowledge. Even with safety measures, they might still produce harmful responses to certain prompts, showing that it’s still hard to fully control their behavior.
A team of researchers from the University of Maryland, Georgia Institute of Technology, University of Bristol, and Google DeepMind propose Mechanistic unlearning. Mechanistic Unlearning is a new AI method that uses mechanistic interpretability to localize and edit specific model components associated with factual recall mechanisms. This approach aims to make edits more robust and reduce unintended side effects.
The study examines methods for removing information from AI models and finds that many fail when prompts or outputs shift. By targeting specific parts of models like Gemma-7B and Gemma-2-9B that are responsible for fact retrieval, a gradient-based approach proves more effective and efficient. This method reduces hidden memory better than others, requiring only a few model changes while generalizing across diverse data. By targeting these components, the method ensures that the unwanted knowledge is effectively unlearned and resists relearning attempts. The researchers demonstrate that this approach leads to more robust edits across different input/output formats and reduces the presence of latent knowledge compared to existing methods.

The researchers carried out experiments to test methods for unlearning and editing information in two datasets: Sports Facts and CounterFact. In the Sports Facts dataset, they worked on removing associations with basketball athletes and changing the sports of 16 athletes to golf. In the CounterFact dataset, they focused on swapping correct answers with incorrect ones for 16 facts. They used two main techniques: Output Tracing (which includes Causal Tracing and Attribution Patching) and Fact Lookup localization. The results showed that manual localization led to better accuracy and strength, especially in multiple-choice tests. The method of manual interpretability was also strong against attempts to relearn the information. Furthermore, analysis of the underlying knowledge suggested that effective editing makes it harder to recover previous information in the model’s layers. Weight masking tests showed that optimization methods mostly change parameters related to extracting facts rather than those used for looking up facts, which emphasizes the need to improve the fact lookup process for better robustness. Thus, this approach aims to make edits more robust and reduce unintended side effects.
In conclusion, this paper presents a promising solution to the problem of robust knowledge unlearning in LLMs by using Mechanistic interpretability to precisely target and edit specific model components, thereby enhancing the effectiveness and robustness of the unlearning process. The proposed work also suggests unlearning/editing as a potential testbed for different interpretability methods, which might sidestep the inherent lack of ground truth in interpretability.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.