#LightBites")




")

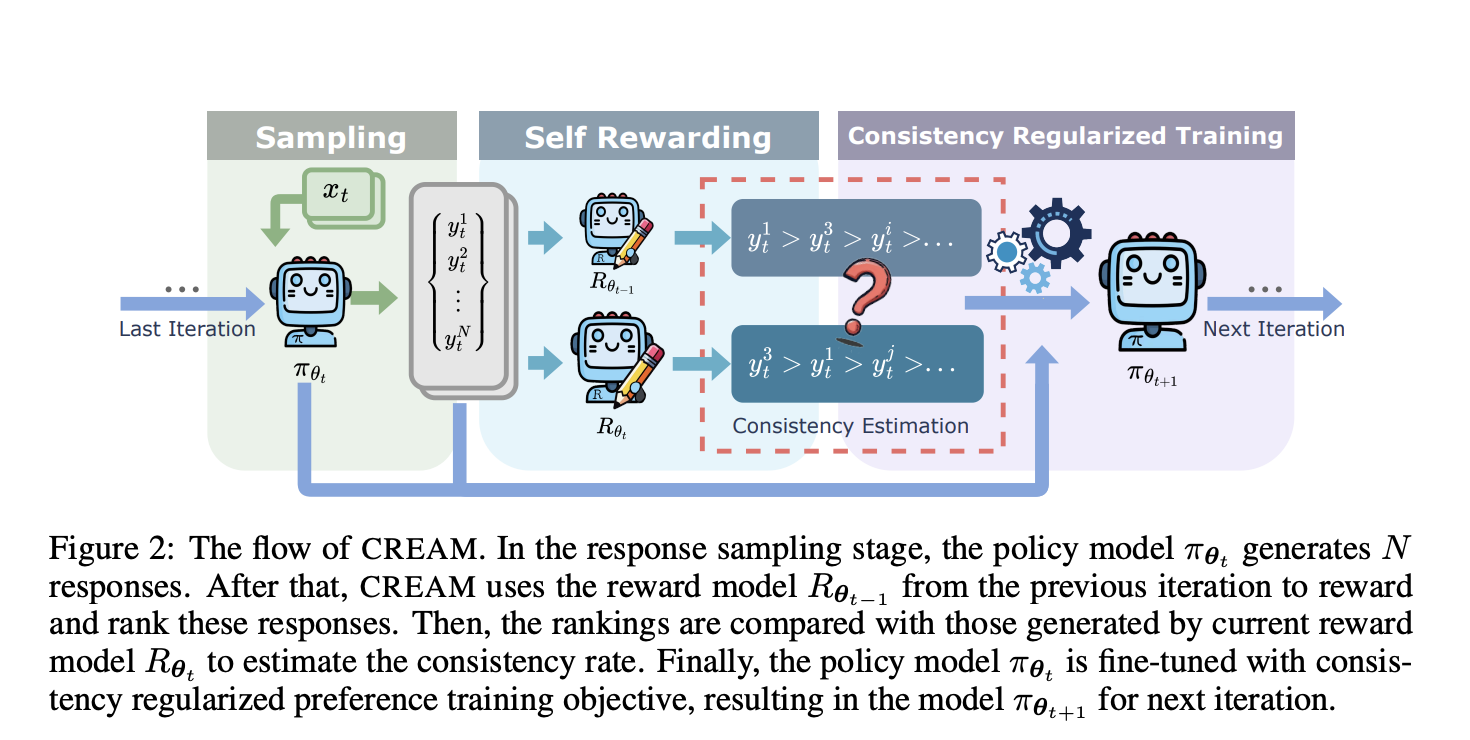
One of the most critical challenges of LLMs is how to align these models with human values and preferences, especially in generated texts. Most generated text outputs by models are inaccurate, biased, or potentially harmful—for example, hallucinations. This misalignment limits the potential usage of LLMs in real-world applications across domains such as education, health, and customer support. This is further compounded by the fact that the bias accrues in LLMs; iterative training processes are bound to make alignment problems worse, and therefore it is not clear whether the output produced will be trusted. This is indeed a very serious challenge for the larger and more effective scaling of LLM modalities applied to real-world applications.
Current solutions to alignment involve methods such as RLHF and direct preference optimization (DPO). RLHF trains a reward model that rewards the LLM through reinforcement learning based on human feedback, while DPO optimizes the LLM directly with annotated preference pairs and does not require a separate model for rewards. Both approaches rely heavily on massive amounts of human-labeled data, which is hard to scale. Self-rewarding language models try to reduce this dependency by automatically generating preference data without human interference. In SRLMs, a single model is usually acting both as a policy model—which generates responses—and as a reward model that ranks these responses. While this has met with some success, its major drawback is that such a process inherently results in bias in the rewards iteration. The more a model has been extensively trained on its self-created preference data in this manner, the more biased the reward system is, and this reduces the reliability of preference data and degrades the overall performance in alignment.
In light of these deficiencies, researchers from the University of North Carolina, Nanyang Technological University, the National University of Singapore, and Microsoft introduced CREAM, which stands for Consistency Regularized Self-Rewarding Language Models. This approach alleviates bias amplification issues in self-rewarding models by incorporating a regularization term on the consistency of rewards across generations during training. The intuition is to bring in consistency regularizers that evaluate the rewards produced by the model across consecutive iterations and use this consistency as guidance for the training process. By contrasting the ranking of responses from the current iteration with those from the previous iteration, CREAM finds and focuses on reliable preference data, hindering the model’s overlearning tendency from noisy or unreliable labels. This novel regularization mechanism reduces the bias and further allows the model to learn more efficiently and effectively from its self-generated preference data. This is a big improvement compared to current self-rewarding methods.
CREAM operates within a generalized iterative preference fine-tuning framework applicable to both self-rewarding and RLHF methods. The consistency regularization works by putting into comparison the ranking of responses produced by the model across consecutive iterations. More precisely, the consistency between rankings coming from the current and previous iterations is measured through Kendall’s Tau coefficient. This consistency score is then inducted into the loss function as a regularization term, which encourages the model to rely more on preference data that has high consistency across iterations. Furthermore, CREAM fine-tunes much smaller LLMs, such as LLaMA-7B, using datasets that are widely available, such as ARC-Easy/Challenge, OpenBookQA, SIQA, and GSM8K. Iteratively, the method strengthens this by using a weighting mechanism for preference data based on its consistency in achieving superior alignment without necessitating large-scale human-labeled datasets.

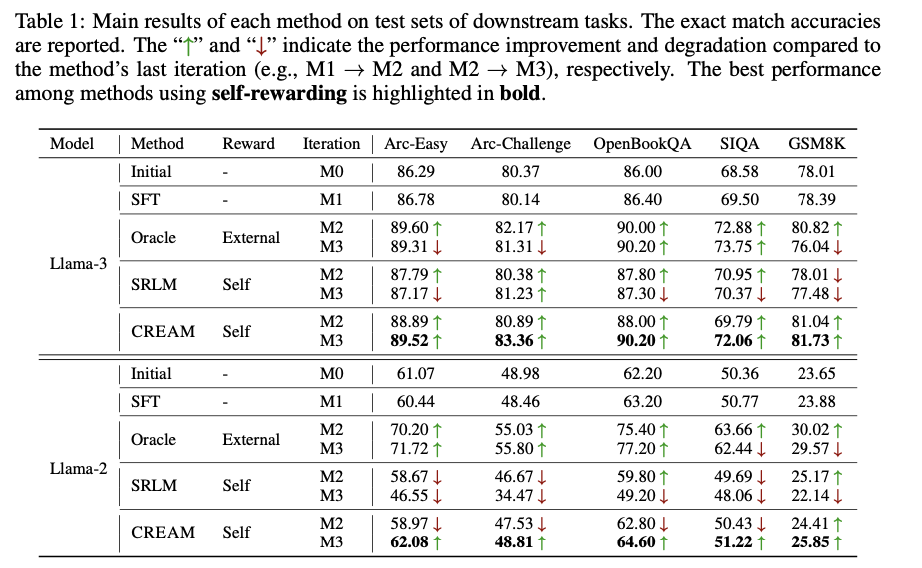
CREAM outperforms the baseline in many downstream tasks in terms of alignment and de-biasing of self-rewarding models. The notable accuracy gains using the method include an increase from 86.78% to 89.52% in ARC-Easy and from 69.50% to 72.06% in SIQA. These consistent improvements over iterations show the power of the consistency regularization mechanism at work. While standard methods of self-rewarding tend to have lower overall consistency of reward and alignment, CREAM outperforms existing models, even in comparison with systems using high-quality external reward models. This also maintained the performance improvement without using any external help, which shows the robustness of the model in generating reliable preference data. Besides, this model keeps improving in terms of accuracy and consistency in reward metrics, truly reflecting the importance of regularization in mitigating reward bias and improving efficiency in self-rewarding. These results further establish CREAM as a strong solution to the alignment problem by providing a scalable and effective method for optimizing large language models.
In conclusion, CREAM offers a novel solution against the challenge of rewarding bias in self-rewarding language models by introducing a consistency regularization mechanism. By paying more attention to dependable and consistent data of preference, CREAM realizes an immense improvement in the alignment of performance, especially for rather small models like LLaMA-7B. While this occludes longer-term reliance on human-annotated data, this method represents an important enhancement toward scalability and efficiency in preference learning. This thus places it as a very valuable contribution to the ongoing development of LLMs toward real-world applications. Empirical results strongly validate that CREAM indeed outperforms existing methods and may have a potential impact on improving alignment and reliability in LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.