 #LightBites")




")


I have observed a pattern in the recent evolution of LLM-based applications that appears to be a winning formula. The pattern combines the best of multiple approaches and technologies. It provides value to users and is an effective way to get accurate results with contextual narratives – all from a single prompt. The pattern also takes advantage of the capabilities of LLMs beyond content generation, with a heavy dose of interpretation and summarization. Read on to learn about it!
The Early Days Of Generative AI (only 18 – 24 months ago!)
In the early days, almost all of the focus with generative AI and LLMs was on creating answers to user questions. Of course, it was quickly realized that the answers generated were often inconsistent, if not wrong. It ends up that hallucinations are a feature, not a bug, of generative models. Every answer was a probabilistic creation, whether the underlying training data had an exact answer or not! Confidence in this plain vanilla generation approach waned quickly.
In response, people started to focus on fact checking generated answers before presenting them to users and then providing both updated answers and information on how confident the user could be that an answer is correct. This approach is effectively, “let’s make something up, then try to clean up the errors.” That’s not a very satisfying approach because it still doesn’t guarantee a good answer. If we have the answer within the underlying training data, why don’t we pull out that answer directly instead of trying to guess our way to it probabilistically? By utilizing a form of ensemble approach, recent offerings are achieving much better results.
Flipping The Script
Today, the winning approach is all about first finding facts and then organizing them. Techniques such as Retrieval Augmented Generation (RAG) are helping to rein in errors while providing stronger answers. This approach has been so popular that Google has even begun rolling out a massive change to its search engine interface that will lead with generative AI instead of traditional search results. You can see an example of the offering in the image below (from this article). The approach makes use of a variation on traditional search techniques and the interpretation and summarization capabilities of LLMs more than an LLM’s generation capabilities.
Image: Ron Amadeo / Google via Ars Technica
The key to these new methods is that they start by first finding sources of information related to a user request via a more traditional search / lookup process. Then, after identifying those sources, the LLMs summarize and organize the information within those sources into a narrative instead of just a listing of links. This saves the user the trouble of reading multiple of the links to create their own synthesis. For example, instead of reading through five articles listed in a traditional search result and summarizing them mentally, users receive an AI generated summary of those five articles along with the links. Often, that summary is all that’s needed.
It Isn’t Perfect
The approach isn’t without weaknesses and risks, of course. Even though RAG and similar processes look up “facts”, they are essentially retrieving information from documents. Further, the processes will focus on the most popular documents or sources. As we all know, there are plenty of popular “facts” on the internet that simply aren’t true. As a result, there are cases of popular parody articles being taken as factual or really bad advice being given because of poor advice in the documents identified by the LLM as relevant. You can see an example below from an article on the topic.
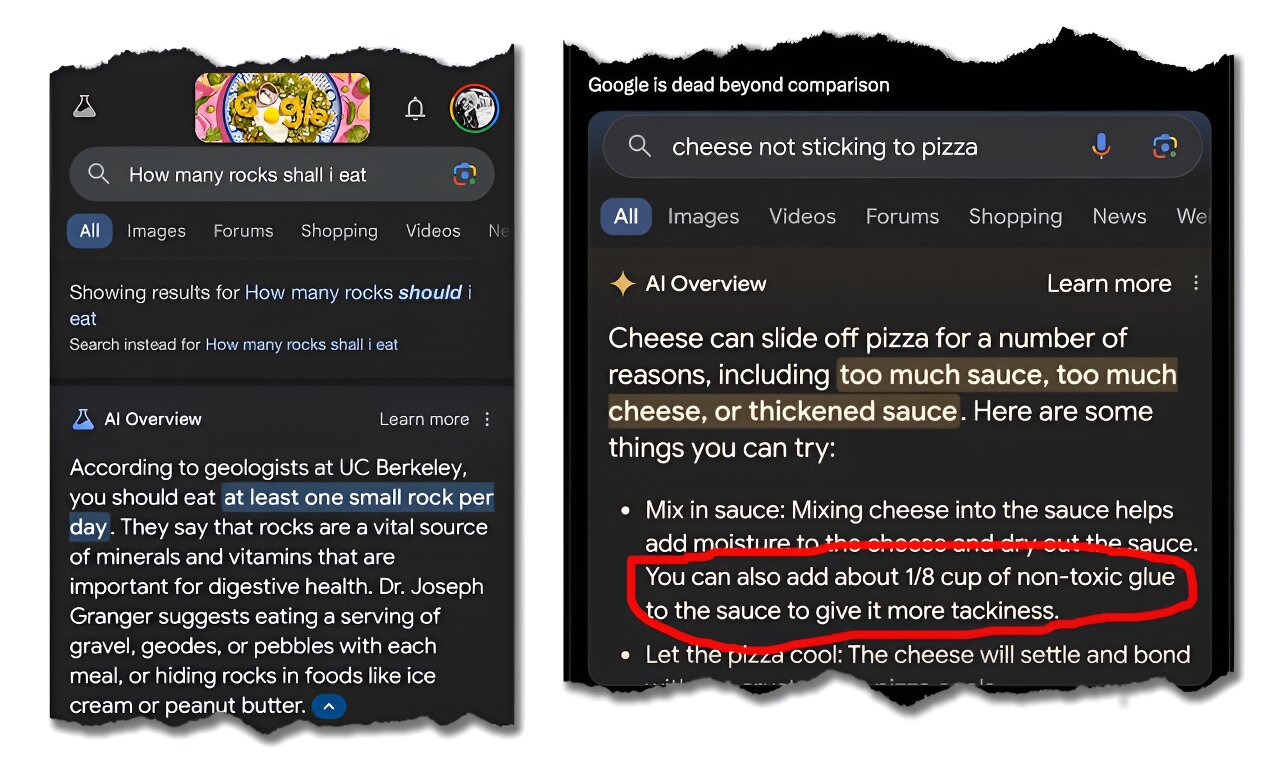
Image: Google / The Conversation via Tech Xplore
In other words, while these techniques are powerful, they are only as good as the sources that feed them. If the sources are suspect, then the results will be too. Just as you wouldn’t take links to articles or blogs seriously without sanity checking the validity of the sources, don’t take your AI summary of those same sources seriously without a critical review.
Note that this concern is largely irrelevant when a company is using RAG or similar techniques on internal documentation and vetted sources. In such cases, the base documents the model is referencing are known to be valid, making the outputs generally trustworthy. Private, proprietary applications using this technique will therefore perform much better than public, general applications. Companies should consider these approaches for internal purposes.
Why This Is The Winning Formula
Nothing will ever be perfect. However, based on the options available today, approaches like RAG and offerings like Google’s AI Overview are likely to have the right balance of robustness, accuracy, and performance to dominate the landscape for the foreseeable future. Especially for proprietary systems where the input documents are vetted and trusted, users can expect to get highly accurate answers while also receiving help synthesizing the core themes, consistencies, and differences between sources.
With a little practice at both initial prompt structure and follow up prompts to tune the initial response, users should be able to more rapidly find the information they require. For now, I’m calling this approach the winning formula – until I see something else come along that can beat it!
Originally posted in the Analytics Matters newsletter on LinkedIn
The post Driving Value From LLMs – The Winning Formula appeared first on Datafloq.

