")








This post is co-written with Tom Dyer, Samuel Barnett and Francisco Azuaje from Genomics England.
Genomics England analyzes sequenced genomes for The National Health Service (NHS) in the United Kingdom, and then equips researchers to use data to advance biological research. As part of its goal to help people live longer, healthier lives, Genomics England is interested in facilitating more accurate identification of cancer subtypes and severity, using machine learning (ML). To explore whether such ML models can perform at higher accuracy when using multiple modalities, such as genomic and imaging data, Genomics England has launched a multi-modal program aimed at enhancing its dataset and also partnered with the the AWS Global Health and Non-profit Go-to-Market (GHN-GTM) Data Science and AWS Professional Services teams to create an automatic cancer sub-typing and survival detection pipeline and explore its accuracy on publicly available data.
In this post, we detail our collaboration in creating two proof of concept (PoC) exercises around multi-modal machine learning for survival analysis and cancer sub-typing, using genomic (gene expression, mutation and copy number variant data) and imaging (histopathology slides) data. We provide insights on interpretability, robustness, and best practices of architecting complex ML workflows on AWS with Amazon SageMaker. These multi-modal pipelines are being used on the Genomics England cancer cohort to enhance our understanding of cancer biomarkers and biology.
1. Data
The PoCs have used the publicly available cancer research data from The Cancer Genome Atlas (TCGA), which contain paired high-throughput genome analysis and diagnostic whole slide images with ground-truth survival outcome and histologic grade labels. Specifically, the PoCs focus on whole slide histopathology images of tissue samples as well as gene expression, copy number variations, and the presence of deleterious genetic variants to perform analysis on two cancer types: Breast cancer (BRCA) and gastrointestinal cancer types (Pan-GI). Table 1 shows the sample sizes for each cancer type.
Table 1. Overview of input data sizes across the different cancer types investigated.
2. Multi-modal machine learning frameworks
The ML pipelines tackling multi-modal subtyping and survival prediction have been built in three phases throughout the PoC exercises. First, a state-of-the-art framework, namely Pathology-Omic Research Platform for Integrative Survival Estimation (PORPOISE) (Chen et al., 2022) was implemented (Section 2.1). This was followed by the proposal, development, and implementation of a novel architecture based on Hierarchical Extremum Encoding (HEEC) (Section 2.2) by AWS, which aimed to mitigate the limitations of PORPOISE. The final phase improved on the results of HEEC and PORPOISE—both of which have been trained in a supervised fashion—using a foundation model trained in a self-supervised manner, namely Hierarchical Image Pyramid Transformer (HIPT) (Chen et al., 2023).
2.1 Pathology-Omic Research Platform for Integrative Survival Estimation (PORPOISE)
PORPOISE (Chen et al., 2022) is a multi-modal ML framework that consists of three sub-network components (see Figure 1 at Chen et al., 2022):
- CLAM component; an attention-based multiple-instance learning network trained on pre-processed whole slid image (WSI) inputs (CLAM, Lu et al., 2021). CLAM extracts features from image patches of size 256×256 using a pre-trained ResNet50.
- A self-normalizing network component for extracting deep molecular features.
- A multi-modal fusion layer for integrating feature representations from 1) and 2) by modelling their pairwise interactions. The joint representations obtained from 3) are then used for undertaking the downstream tasks such as survival analysis and cancer-subtyping.
Despite being performant, PORPOISE was observed to output reduced multi-modal performance than single best modality (imaging) performance alone when gene expression data was excluded from the genomic features while performing survival analysis for Pan-GI data (Figure 2). A possible explanation is that the model has difficulty dealing with the extremely high dimensional, sparse genomic data without overfitting.
2.2. Hierarchical Extremum Encoding (HEEC): A novel supervised multi-modal ML framework
To mitigate the limitations of PORPOISE, AWS has developed a novel model structure, HEEC, which is based on three ideas:
- Using tree ensembles (LightGBM) to mitigate the sparsity and overfitting issue observed when training PORPOISE (as observed by Grinsztajn et al., 2022, tree-based models tend to overfit less when confronted with high-dimensional data with many largely uninformative features).
- Representation construction using a novel encoding scheme (extremum encoding) that preserves spatial relationships and thus interpretability.
- Hierarchical learning to allow representations at multiple spatial scales.
 Figure 1. Hierarchical Extremum Encoding (HEEC) of pathomic representations.
Figure 1. Hierarchical Extremum Encoding (HEEC) of pathomic representations.
Figure 1 summarizes the HEEC architecture: starting from the bottom (and clockwise): Every input WSI is cut up into patches of size 4096×4096 and 256×256 pixels in a hierarchical manner and all stacks of patches are fed through ResNet50 to obtain embedding vectors. Additionally, nucleus-level representations (of size 64×64 pixels) are extracted by a graph neural network (GNNs), allowing local nucleus neighborhoods and their spatial relationships to be taken into account. This is followed by filtering for redundancy: Patch embeddings that are important are selected using positive-unlabeled learning, and GNN importance filtering is used for retaining the top nuclei features. The resulting hierarchical embeddings are coded using extremum encoding: the maxima and minima across the embeddings are taken in each vector entry, resulting in a single vector of maxima and minima per WSI. This encoding scheme allows keeping exact track of spatial relationships for each entry in the resulting representation vectors because the model can backtrack each vector entry to a specific patch, and thus to a specific coordinate in the image.
On the genomics side, importance filtering is applied based on excluding features that don’t correlate with the prediction target. The remaining features are horizontally appended to the pathology features, and a gradient boosted decision tree classifier (LightGBM) is applied to achieve predictive analysis.
HEEC architecture is interpretable out of the box, because HEEC embeddings possess implicit spatial information and the LightGBM model supports feature importance, allowing the filtering of the most important features for accurate prediction and backtracking to their location of origin. This location can be visually highlighted on the histology slide to be presented to expert pathologists for verification. Table 2 and Figure 2 show performance results of PORPOISE and HEEC, which show that HEEC is the only algorithm that outperforms the results of the best-performing single modality by combining multiple modalities.
 Table 2. Classification and survival prediction performance of the two implemented multi-modal ML models on TCGA data. *Although Chen et al., 2022 provide some interpretability, the proposed attention visualization heatmaps have been deemed difficult to interpret from the pathologist point of view by Genomics England domain experts.
Table 2. Classification and survival prediction performance of the two implemented multi-modal ML models on TCGA data. *Although Chen et al., 2022 provide some interpretability, the proposed attention visualization heatmaps have been deemed difficult to interpret from the pathologist point of view by Genomics England domain experts.
 Figure 2. Comparison of performance (AUC) across individual modalities for survival analysis, when excluding the gene expression data. This matches the setting encountered by GEL in practice (GEL’s internal dataset has no gene expression data)
Figure 2. Comparison of performance (AUC) across individual modalities for survival analysis, when excluding the gene expression data. This matches the setting encountered by GEL in practice (GEL’s internal dataset has no gene expression data)
2.3. Improvements using foundation models
Despite yielding promising results, PORPOISE and HEEC algorithms use backbone architectures trained using supervised learning (for example, ImageNet pre-trained ResNet50). To further improve performance, a self-supervised learning-based approach, namely Hierarchical Image Pyramid Transformer (HIPT) (Chen et al., 2023), has been investigated in the final stage of the PoC exercises. Note that HIPT is currently limited to the hierarchical self-supervised learning of the imaging modality (WSIs) and further work includes expansion of self-supervised learning for the genomic modality.
HIPT starts by defining a hierarchy of patches composed of non-overlapping regions of size 16×16, 256×256, and 4096×4096 pixels (see Figure 2 at Chen et al., 2023). The lowest-layer features are extracted from the smallest patches (16×16) using a self-supervised learning algorithm based on DINO with a Vision Transformer (ViT) backbone. For each 256×256 region, the lowest-layer features are then aggregated using a global pooling layer. The aggregated features constitute the (new input) features for the middle-level in the hierarchy, where the process of self-supervised learning followed by global pooling is repeated and the aggregated output features form the input features belonging to the 4096×4096 region. These input features go through self-supervised learning one last time, and the final embeddings are obtained using global attention pooling. After pre-training is completed, fine-tuning is employed only on the final layer of the hierarchy (acting on 4096×4096 regions) using multiple instance learning.
Genomics England investigated whether using HIPT embeddings would be better than using the ImageNet pretrained ResNet50 encoder, and initial experiments have shown a gain in Harrels C-index of approximately 0.05 per cancer type in survival analysis. The embeddings offer other benefits as well. Such as being smaller—meaning that models train faster and the features have a smaller footprint.
3. Architecture on AWS
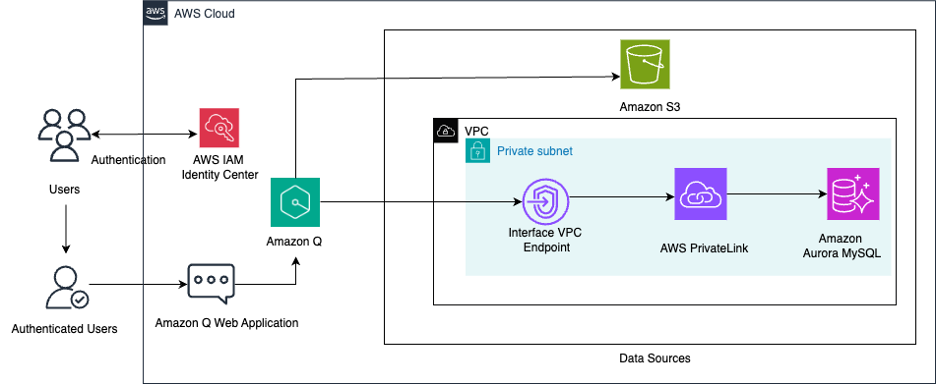
As part of the PoCs, we built a reference architecture (illustrated in Figure 3) for multi-modal ML using SageMaker, a platform for building training, and deploying ML models, with fully managed infrastructure, tools, and workflows. We aimed to demonstrate some general, reusable patterns that are independent of the specific algorithms:
- Decouple data pre-processing and feature computation from model training: In our use case, we process the pathology images into numerical feature representations once, we then store the resulting feature vectors in Amazon Simple Storage Service (Amazon S3) and reuse them to train different models. Analogously, we have a second processing branch that processes and extracts features from the genomic data.
- Decouple model training from inference: As we experiment with different model structures and hyperparameters, we keep track of model versions, hyperparameters, and metrics in SageMaker model registry. We refer to the registry to review our experiments and choose which models to deploy for inference.
- Wrap long-running computations inside containers and delegate their execution to SageMaker: Any long-running computation benefits from this pattern, whether it’s for data processing, model training, or batch inference. In this way, there’s no need to manage the underlying compute resources for running the containers. Cost is reduced through a pay-as-you-go model (resources are destroyed after a container has finished running) and the architecture is easily scalable to run multiple jobs in parallel.
- Orchestrate multiple containerized jobs into SageMaker pipelines: We build a pipeline once and run it multiple times with different parametrization. Hence, pipeline invocations can be referred to at a higher-level of abstraction, without having to constantly monitor the status of its long-running constituent jobs.
- Delegate hyperparameter tuning to SageMaker using a hyperparameter tuning job: A tuning job is a family of related training jobs (all managed by SageMaker) that efficiently explore the hyperparameter space. These training jobs take the same input data for training and validation, but each one is run with different hyperparameters for the learning algorithm. Which hyperparameter values to explore at each iteration are automatically chosen by SageMaker.
3.1 Separation between development and production environments
In general, we advise to do all development work outside of a production environment, because this minimizes the risk of leakage and corruption of sensitive production data and the production environment isn’t contaminated with intermediate data and software artifacts that obfuscate lineage tracking. If data scientists require access to production data during developmental stages, for tasks such as exploratory analysis and modelling work, there are numerous strategies that can be employed to minimize risk. One effective strategy is to employ data masking or synthetic data generation techniques in the testing environment to simulate real-world scenarios without compromising sensitive data. Furthermore, production level data can be securely moved into an independent environment for analysis. Access controls and permissions can be implemented to restrict the flow of data between environments, maintaining separation and ensuring minimal access rights.
Genomics England has created two separate ML environments for testing and production level interaction with data. Each environment sits in its own isolated AWS account. The test environment mimics the production environment in its data storage strategy, but contains synthetic data void of personally identifiable information (PII) or protected health information (PHI), instead of production-level data. This test environment is used for developing essential infrastructure components and refining best practices in a controlled setting, which can be tested with synthetic data before deploying to production. Strict access controls, including role-based permissions employing principles of least privilege, are implemented in all environments to ensure that only authorized personnel can interact with sensitive data or modify deployed resources.
3.2 Automation with CI/CD pipelines
On a related note, we advise ML developers to use infrastructure-as-code to describe the resources that are deployed in their AWS accounts and use continuous integration and delivery (CI/CD) pipelines to automate code quality checks, unit testing, and the creation of artifacts, such as container images. Then, also configure the CI/CD pipelines to automatically deploy the created artifacts into the target AWS accounts, whether they’re for development or for production. These well-established automation techniques minimize errors related to manual deployments and maximize the reproducibility between development and production environments.
Genomics England has investigated the use of CI/CD pipelines for automated deployment of platform resources, as well as automated testing of code.
 Figure 3. Overview of the AWS reference architecture employed for multi-modal ML in the cloud
Figure 3. Overview of the AWS reference architecture employed for multi-modal ML in the cloud
4. Conclusion
Genomics England has a long history of working with genomics data, however the inclusion of imaging data adds additional complexity and potential. The two PoCs outlined in this post have been essential in launching Genomics England’s efforts in creating a multi-modal environment that facilitates ML development for the purpose of tackling cancer. The implementation of state-of-the-art models in Genomics England’s multi-modal environment and assistance in developing robust practices will ensure that users are maximally enabled in their research.
“At Genomics England, our mission is to realize the enormous potential of genomic and multi-modal information to further precision medicine and push the boundaries to realize the enormous potential of AWS cloud computing in its success”.
– Dr Prabhu Arumugam, Director of Clinical data and imaging, Genomics England
Acknowledgements
The results published in this blog post are in whole or part based upon data generated by the TCGA Research Network: https://www.cancer.gov/tcga.
About the Authors
 Cemre Zor, PhD, is a senior healthcare data scientist at Amazon Web Services. Cemre holds a PhD in theoretical machine learning and postdoctoral experiences on machine learning for computer vision and healthcare. She works with healthcare and life sciences customers globally to support them with machine learning modelling and advanced analytics approaches while tackling real-world healthcare problems.
Cemre Zor, PhD, is a senior healthcare data scientist at Amazon Web Services. Cemre holds a PhD in theoretical machine learning and postdoctoral experiences on machine learning for computer vision and healthcare. She works with healthcare and life sciences customers globally to support them with machine learning modelling and advanced analytics approaches while tackling real-world healthcare problems.
 Tamas Madl, PhD, is a former senior healthcare data scientist and business development lead at Amazon Web Services, with academic as well as industry experience at the intersection between healthcare and machine learning. Tamas helped customers in the Healthcare and Life Science vertical to innovate through the adoption of Machine Learning. He received his PhD in Computer Science from the University of Manchester.
Tamas Madl, PhD, is a former senior healthcare data scientist and business development lead at Amazon Web Services, with academic as well as industry experience at the intersection between healthcare and machine learning. Tamas helped customers in the Healthcare and Life Science vertical to innovate through the adoption of Machine Learning. He received his PhD in Computer Science from the University of Manchester.
 Epameinondas Fritzilas, PhD, is a senior consultant at Amazon Web Services. He works hands-on with customers to design and build solutions for data analytics and AI applications in healthcare. He holds a PhD in bioinformatics and fifteen years of industry experience in the biotech and healthcare sectors.
Epameinondas Fritzilas, PhD, is a senior consultant at Amazon Web Services. He works hands-on with customers to design and build solutions for data analytics and AI applications in healthcare. He holds a PhD in bioinformatics and fifteen years of industry experience in the biotech and healthcare sectors.
 Lou Warnett is a healthcare data scientist at Amazon Web Services. He assists healthcare and life sciences customers from across the world in tackling some of their most pressing challenges using data science, machine learning and AI, with a particular emphasis more recently on generative AI. Prior to joining AWS, Lou received a master’s in Mathematics and Computing at Imperial College London.
Lou Warnett is a healthcare data scientist at Amazon Web Services. He assists healthcare and life sciences customers from across the world in tackling some of their most pressing challenges using data science, machine learning and AI, with a particular emphasis more recently on generative AI. Prior to joining AWS, Lou received a master’s in Mathematics and Computing at Imperial College London.
 Sam Price is a Professional Services consultant specializing in AI/ML and data analytics at Amazon Web Services. He works closely with public sector customers in healthcare and life sciences to solve challenging problems. When not doing this, Sam enjoys playing guitar and tennis, and seeing his favorite indie bands.
Sam Price is a Professional Services consultant specializing in AI/ML and data analytics at Amazon Web Services. He works closely with public sector customers in healthcare and life sciences to solve challenging problems. When not doing this, Sam enjoys playing guitar and tennis, and seeing his favorite indie bands.
 Shreya Ruparelia is a data & AI consultant at Amazon Web Services, specialising in data science and machine learning, with a focus on developing GenAI applications. She collaborates with public sector healthcare organisations to create innovative AI-driven solutions. In her free time, Shreya enjoys activities such as playing tennis, swimming, exploring new countries and taking walks with the family dog, Buddy.
Shreya Ruparelia is a data & AI consultant at Amazon Web Services, specialising in data science and machine learning, with a focus on developing GenAI applications. She collaborates with public sector healthcare organisations to create innovative AI-driven solutions. In her free time, Shreya enjoys activities such as playing tennis, swimming, exploring new countries and taking walks with the family dog, Buddy.
 Pablo Nicolas Nunez Polcher, MSc, is a senior solutions architect working for the Public Sector team with Amazon Web Services. Pablo focuses on helping healthcare public sector customers build new, innovative products on AWS in accordance with best practices. He received his M.Sc. in Biological Sciences from Universidad de Buenos Aires. In his spare time, he enjoys cycling and tinkering with ML-enabled embedded devices.
Pablo Nicolas Nunez Polcher, MSc, is a senior solutions architect working for the Public Sector team with Amazon Web Services. Pablo focuses on helping healthcare public sector customers build new, innovative products on AWS in accordance with best practices. He received his M.Sc. in Biological Sciences from Universidad de Buenos Aires. In his spare time, he enjoys cycling and tinkering with ML-enabled embedded devices.
 Matthew Howard is the head of Healthcare Data Science and part of the Global Health and Non-Profits team in Amazon Web Services. He focuses on how data, machine learning and artificial intelligence can transform health systems and improve patient outcomes. He leads a team of applied data scientists who work with customers to develop AI-based healthcare solutions. Matthew holds a PhD in Biological Sciences from Imperial College London.
Matthew Howard is the head of Healthcare Data Science and part of the Global Health and Non-Profits team in Amazon Web Services. He focuses on how data, machine learning and artificial intelligence can transform health systems and improve patient outcomes. He leads a team of applied data scientists who work with customers to develop AI-based healthcare solutions. Matthew holds a PhD in Biological Sciences from Imperial College London.
 Tom Dyer is a Senior Product Manager at Genomics England. And was previously an Applied Machine Learning Engineer working within the Multimodal squad. His work focussed on building multimodal learning frameworks that allow users to rapidly scale research in the cloud. He also works on developing ML tooling to organise pathology image datasets and explain model predictions on a cohort level
Tom Dyer is a Senior Product Manager at Genomics England. And was previously an Applied Machine Learning Engineer working within the Multimodal squad. His work focussed on building multimodal learning frameworks that allow users to rapidly scale research in the cloud. He also works on developing ML tooling to organise pathology image datasets and explain model predictions on a cohort level
 Samuel Barnett is an applied machine learning engineer with Genomics England working on improving healthcare with machine learning. He is embedded with the Multimodal squad and is part of an ongoing effort to show the value of combing genomic, imaging, and text based data in machine learning models.
Samuel Barnett is an applied machine learning engineer with Genomics England working on improving healthcare with machine learning. He is embedded with the Multimodal squad and is part of an ongoing effort to show the value of combing genomic, imaging, and text based data in machine learning models.
 Prabhu Arumugam is the former Director of Clinical Data Imaging at Genomics England. Having joined the organization in 2019, Prabhu trained in medicine St. Bartholomew’s and the Royal London. He trained in Histopathology and completed his PhD at The Barts Cancer Institute on pancreatic pathology.
Prabhu Arumugam is the former Director of Clinical Data Imaging at Genomics England. Having joined the organization in 2019, Prabhu trained in medicine St. Bartholomew’s and the Royal London. He trained in Histopathology and completed his PhD at The Barts Cancer Institute on pancreatic pathology.
 Francisco Azuaje, PhD, is the director of bioinformatics at Genomics England, where he provides cross-cutting leadership in strategy and research with a focus on data science and AI. With a career covering academia, the pharmaceutical industry, and the public sector, he has wide experience leading multidisciplinary teams in solving challenges involving diverse data sources and computational modelling approaches. With his expertise in bioinformatics and applied AI, Dr. Azuaje enables the translation of complex data into insights that can improve patient outcomes.
Francisco Azuaje, PhD, is the director of bioinformatics at Genomics England, where he provides cross-cutting leadership in strategy and research with a focus on data science and AI. With a career covering academia, the pharmaceutical industry, and the public sector, he has wide experience leading multidisciplinary teams in solving challenges involving diverse data sources and computational modelling approaches. With his expertise in bioinformatics and applied AI, Dr. Azuaje enables the translation of complex data into insights that can improve patient outcomes.