")







This post was co-authored by Brian Curry (Founder and Head of Products at OCX Cognition) and Sandhya MN (Data Science Lead at InfoGain)
OCX Cognition is a San Francisco Bay Area-based startup, offering a commercial B2B software as a service (SaaS) product called Spectrum AI. Spectrum AI is a predictive (generative) CX analytics platform for enterprises. OCX’s solutions are developed in collaboration with Infogain, an AWS Advanced Tier Partner. Infogain works with OCX Cognition as an integrated product team, providing human-centered software engineering services and expertise in software development, microservices, automation, Internet of Things (IoT), and artificial intelligence.
The Spectrum AI platform combines customer attitudes with customers’ operational data and uses machine learning (ML) to generate continuous insight on CX. OCX built Spectrum AI on AWS because AWS offered a wide range of tools, elastic computing, and an ML environment that would keep pace with evolving needs.
In this post, we discuss how OCX Cognition with the support of Infogain and OCX’s AWS account team improved their end customer experience and reduced time to value by automating and orchestrating ML functions that supported Spectrum AI’s CX analytics. Using AWS Step Functions, the AWS Step Functions Data Science SDK for Python, and Amazon SageMaker Experiments, OCX Cognition reduced ML model development time from 6 weeks to 2 weeks and reduced ML model update time from 4 days to near-real time.
Background
The Spectrum AI platform has to produce models tuned for hundreds of different generative CX scores for each customer, and these scores need to be uniquely computed for tens of thousands of active accounts. As time passes and new experiences accumulate, the platform has to update these scores based on new data inputs. After new scores are produced, OCX and Infogain compute the relative impact of each underlying operational metric in the prediction. Amazon SageMaker is a web-based integrated development environment (IDE) that allows you to build, train, and deploy ML models for any use case with fully managed infrastructure, tools, and workflows. With SageMaker, the OCX-Infogain team developed their solution using shared code libraries across individually maintained Jupyter notebooks in Amazon SageMaker Studio.
The problem: Scaling the solution for multiple customers
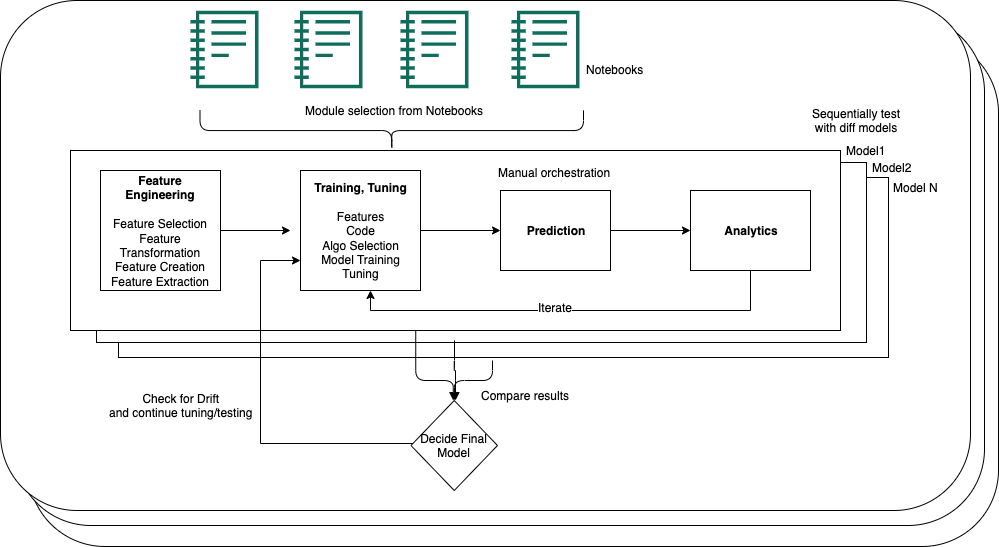
While the initial R&D proved successful, scaling posed a challenge. OCX and Infogain’s ML development involved multiple steps: feature engineering, model training, prediction, and the generation of analytics. The code for modules resided in multiple notebooks, and running these notebooks was manual, with no orchestration tool in place. For every new customer, the OCX-Infogain team spent 6 weeks per customer on model development time because libraries couldn’t be reused. Due to the amount of time spent on model development, the OCX-Infogain team needed an automated and scalable solution that operated as a singular platform using unique configurations for each of their customers.
The following architecture diagram depicts OCX’s initial ML model development and update processes.
Solution overview
To simplify the ML process, the OCX-Infogain team worked with the AWS account team to develop a custom declarative ML framework to replace all repetitive code. This reduced the need to develop new low-level ML code. New libraries could be reused for multiple customers by configuring the data appropriately for each customer through YAML files.
While this high-level code continues to be developed initially in Studio using Jupyter notebooks, it’s then converted to Python (.py files), and the SageMaker platform is used to build a Docker image with BYO (bring your own) containers. The Docker images are then pushed to Amazon Elastic Container Registry (Amazon ECR) as a preparatory step. Finally, the code is run using Step Functions.
The AWS account team recommended the Step Functions Data Science SDK and SageMaker Experiments to automate feature engineering, model training, and model deployment. The Step Functions Data Science SDK was used to generate the step functions programmatically. The OCX-Infogain team learned how to use features like Parallel and MAP within Step Functions to orchestrate a large number of training and processing jobs in parallel, which reduces the runtime. This was combined with Experiments, which functions as an analytics tool, tracking multiple ML candidates and hyperparameter tuning variations. These built-in analytics allowed the OCX-Infogain team to compare multiple metrics at runtime and identify best-performing models on the fly.
The following architecture diagram shows the MLOps pipeline developed for the model creation cycle.

The Step Functions Data Science SDK is used to analyze and compare multiple model training algorithms. The state machine runs multiple models in parallel, and each model output is logged into Experiments. When model training is complete, the results of multiple experiments are retrieved and compared using the SDK. The following screenshots show how the best performing model is selected for each stage.


The following are the high-level steps of the ML lifecycle:
- ML developers push their code into libraries on the Gitlab repository when development in Studio is complete.
- AWS CodePipeline is used to check out the appropriate code from the Gitlab repository.
- A Docker image is prepared using this code and pushed to Amazon ECR for serverless computing.
- Step Functions is used to run steps using Amazon SageMaker Processing jobs. Here, multiple independent tasks are run in parallel:
- Feature engineering is performed, and the features are stored in the feature store.
- Model training is run, with multiple algorithms and several combinations of hyperparameters utilizing the YAML configuration file.
- The training step function is designed to have heavy parallelism. The models for each journey stage are run in parallel. This is depicted in the following diagram.

- Model results are then logged in Experiments. The best-performing model is selected and pushed to the model registry.
- Predictions are made using the best-performing models for each CX analytic we generate.
- Hundreds of analytics are generated and then handed off for publication in a data warehouse hosted on AWS.
Results
With this approach, OCX Cognition has automated and accelerated their ML processing. By replacing labor-intensive manual processes and highly repetitive development burdens, the cost per customer is reduced by over 60{8f70a6f82286a397ea7021ad8fff2990e4c07835f2e47703b7976f5a37e4ea20}. This also allows OCX to scale their software business by tripling overall capacity and doubling capacity for simultaneous onboarding of customers. OCX’s automating of their ML processing unlocks new potential to grow through customer acquisition. Using SageMaker Experiments to track model training is critical to identifying the best set of models to use and take to production. For their customers, this new solution provides not only an 8{8f70a6f82286a397ea7021ad8fff2990e4c07835f2e47703b7976f5a37e4ea20} improvement in ML performance, but a 63{8f70a6f82286a397ea7021ad8fff2990e4c07835f2e47703b7976f5a37e4ea20} improvement in time to value. New customer onboarding and the initial model generation has improved from 6 weeks to 2 weeks. Once built and in place, OCX begins to continuously regenerate the CX analytics as new input data arrives from the customer. These update cycles have improved from 4 days to near-real time
Conclusion
In this post, we showed how OCX Cognition and Infogain utilized Step Functions, the Step Functions Data Science SDK for Python, and Sagemaker Experiments in conjunction with Sagemaker Studio to reduce time to value for the OCX-InfoGain team in developing and updating CX analytics models for their customers.
To get started with these services, refer to Amazon SageMaker, AWS Step Functions Data Science Python SDK, AWS Step Functions, and Manage Machine Learning with Amazon SageMaker Experiments.
About the Authors
 Brian Curry is currently a founder and Head of Products at OCX Cognition, where we are building a machine learning platform for customer analytics. Brian has more than a decade of experience leading cloud solutions and design-centered product organizations.
Brian Curry is currently a founder and Head of Products at OCX Cognition, where we are building a machine learning platform for customer analytics. Brian has more than a decade of experience leading cloud solutions and design-centered product organizations.
 Sandhya M N is part of Infogain and leads the Data Science team for OCX. She is a seasoned software development leader with extensive experience across multiple technologies and industry domains. She is passionate about staying up to date with technology and using it to deliver business value to customers.
Sandhya M N is part of Infogain and leads the Data Science team for OCX. She is a seasoned software development leader with extensive experience across multiple technologies and industry domains. She is passionate about staying up to date with technology and using it to deliver business value to customers.
 Prashanth Ganapathy is a Senior Solutions Architect in the Small Medium Business (SMB) segment at AWS. He enjoys learning about AWS AI/ML services and helping customers meet their business outcomes by building solutions for them. Outside of work, Prashanth enjoys photography, travel, and trying out different cuisines.
Prashanth Ganapathy is a Senior Solutions Architect in the Small Medium Business (SMB) segment at AWS. He enjoys learning about AWS AI/ML services and helping customers meet their business outcomes by building solutions for them. Outside of work, Prashanth enjoys photography, travel, and trying out different cuisines.
 Sabha Parameswaran is a Senior Solutions Architect at AWS with over 20 years of deep experience in enterprise application integration, microservices, containers and distributed systems performance tuning, prototyping, and more. He is based out of the San Francisco Bay Area. At AWS, he is focused on helping customers in their cloud journey and is also actively involved in microservices and serverless-based architecture and frameworks.
Sabha Parameswaran is a Senior Solutions Architect at AWS with over 20 years of deep experience in enterprise application integration, microservices, containers and distributed systems performance tuning, prototyping, and more. He is based out of the San Francisco Bay Area. At AWS, he is focused on helping customers in their cloud journey and is also actively involved in microservices and serverless-based architecture and frameworks.
 Vaishnavi Ganesan is a Solutions Architect at AWS based in the San Francisco Bay Area. She is focused on helping Commercial Segment customers on their cloud journey and is passionate about security in the cloud. Outside of work, Vaishnavi enjoys traveling, hiking, and trying out various coffee roasters.
Vaishnavi Ganesan is a Solutions Architect at AWS based in the San Francisco Bay Area. She is focused on helping Commercial Segment customers on their cloud journey and is passionate about security in the cloud. Outside of work, Vaishnavi enjoys traveling, hiking, and trying out various coffee roasters.
 Ajay Swaminathan is an Account Manager II at AWS. He is an advocate for Commercial Segment customers, providing the right financial, business innovation, and technical resources in accordance with his customers’ goals. Outside of work, Ajay is passionate about skiing, dubstep and drum and bass music, and basketball.
Ajay Swaminathan is an Account Manager II at AWS. He is an advocate for Commercial Segment customers, providing the right financial, business innovation, and technical resources in accordance with his customers’ goals. Outside of work, Ajay is passionate about skiing, dubstep and drum and bass music, and basketball.