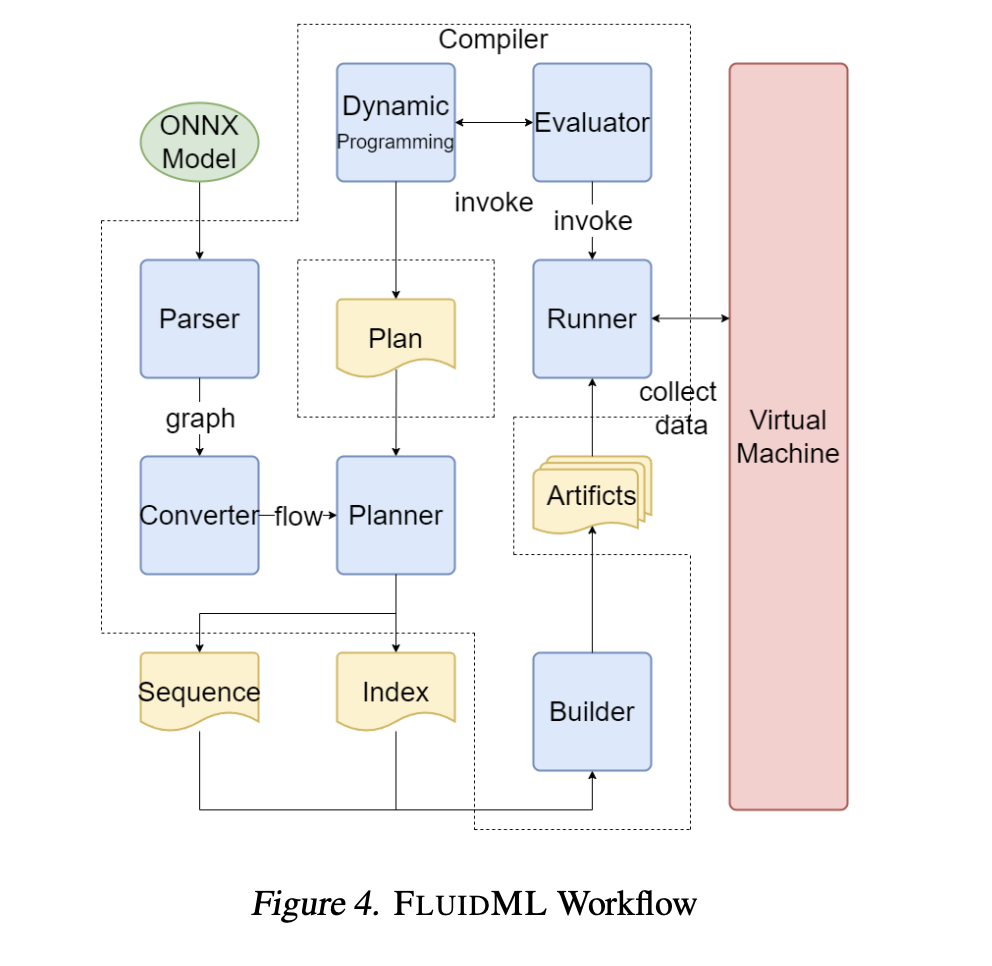
")








DeepNash learns to play Stratego from scratch by combining game theory and model-free deep RL
Game-playing artificial intelligence (AI) systems have advanced to a new frontier. Stratego, the classic board game that’s more complex than chess and Go, and craftier than poker, has now been mastered. Published in Science, we present DeepNash, an AI agent that learned the game from scratch to a human expert level by playing against itself.
DeepNash uses a novel approach, based on game theory and model-free deep reinforcement learning. Its play style converges to a Nash equilibrium, which means its play is very hard for an opponent to exploit. So hard, in fact, that DeepNash has reached an all-time top-three ranking among human experts on the world’s biggest online Stratego platform, Gravon.
Board games have historically been a measure of progress in the field of AI, allowing us to study how humans and machines develop and execute strategies in a controlled environment. Unlike chess and Go, Stratego is a game of imperfect information: players cannot directly observe the identities of their opponent’s pieces.
This complexity has meant that other AI-based Stratego systems have struggled to get beyond amateur level. It also means that a very successful AI technique called “game tree search”, previously used to master many games of perfect information, is not sufficiently scalable for Stratego. For this reason, DeepNash goes far beyond game tree search altogether.
The value of mastering Stratego goes beyond gaming. In pursuit of our mission of solving intelligence to advance science and benefit humanity, we need to build advanced AI systems that can operate in complex, real-world situations with limited information of other agents and people. Our paper shows how DeepNash can be applied in situations of uncertainty and successfully balance outcomes to help solve complex problems.
Getting to know Stratego
Stratego is a turn-based, capture-the-flag game. It’s a game of bluff and tactics, of information gathering and subtle manoeuvring. And it’s a zero-sum game, so any gain by one player represents a loss of the same magnitude for their opponent.
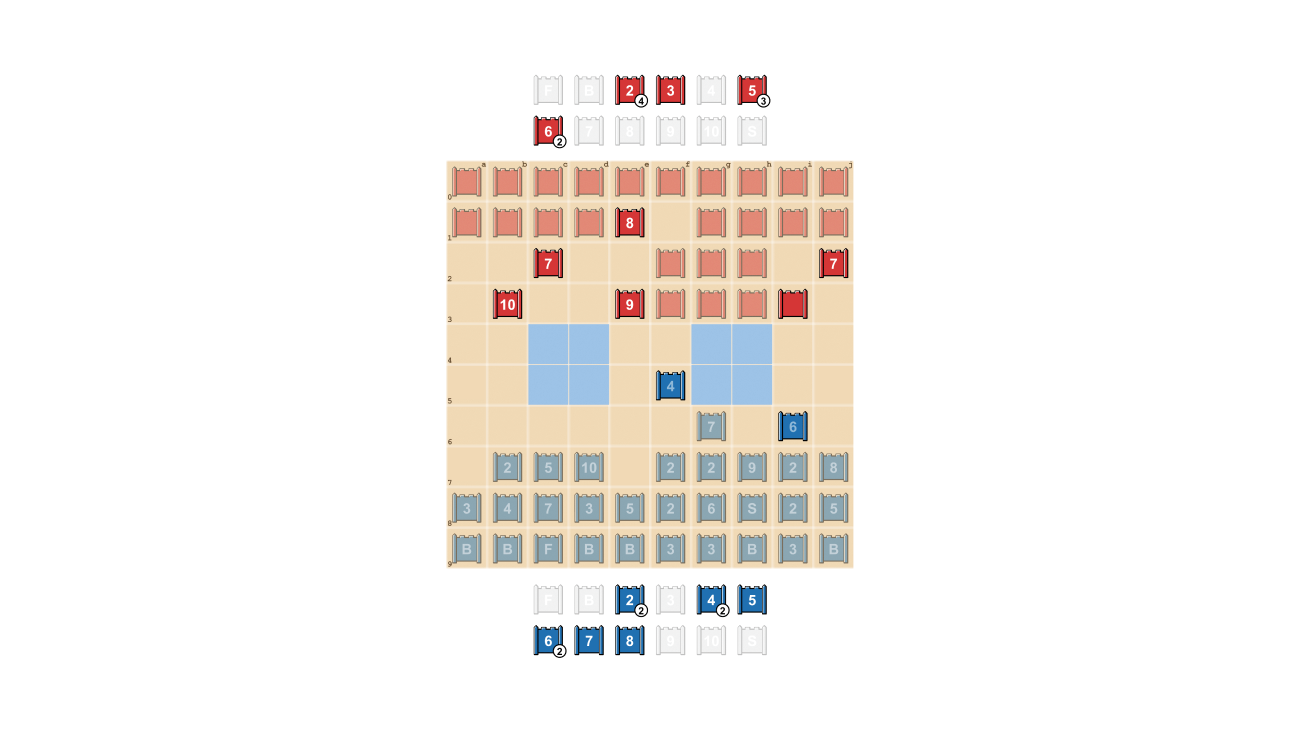
Stratego is challenging for AI, in part, because it’s a game of imperfect information. Both players start by arranging their 40 playing pieces in whatever starting formation they like, initially hidden from one another as the game begins. Since both players don’t have access to the same knowledge, they need to balance all possible outcomes when making a decision – providing a challenging benchmark for studying strategic interactions. The types of pieces and their rankings are shown below.
Middle: A possible starting formation. Notice how the Flag is tucked away safely at the back, flanked by protective Bombs. The two pale blue areas are “lakes” and are never entered.
Right: A game in play, showing Blue’s Spy capturing Red’s 10.
Information is hard won in Stratego. The identity of an opponent’s piece is typically revealed only when it meets the other player on the battlefield. This is in stark contrast to games of perfect information such as chess or Go, in which the location and identity of every piece is known to both players.
The machine learning approaches that work so well on perfect information games, such as DeepMind’s AlphaZero, are not easily transferred to Stratego. The need to make decisions with imperfect information, and the potential to bluff, makes Stratego more akin to Texas hold’em poker and requires a human-like capacity once noted by the American writer Jack London: “Life is not always a matter of holding good cards, but sometimes, playing a poor hand well.”
The AI techniques that work so well in games like Texas hold’em don’t transfer to Stratego, however, because of the sheer length of the game – often hundreds of moves before a player wins. Reasoning in Stratego must be done over a large number of sequential actions with no obvious insight into how each action contributes to the final outcome.
Finally, the number of possible game states (expressed as “game tree complexity”) is off the chart compared with chess, Go and poker, making it incredibly difficult to solve. This is what excited us about Stratego, and why it has represented a decades-long challenge to the AI community.

Seeking an equilibrium
DeepNash employs a novel approach based on a combination of game theory and model-free deep reinforcement learning. “Model-free” means DeepNash is not attempting to explicitly model its opponent’s private game-state during the game. In the early stages of the game in particular, when DeepNash knows little about its opponent’s pieces, such modelling would be ineffective, if not impossible.
And because the game tree complexity of Stratego is so vast, DeepNash cannot employ a stalwart approach of AI-based gaming – Monte Carlo tree search. Tree search has been a key ingredient of many landmark achievements in AI for less complex board games, and poker.
Instead, DeepNash is powered by a new game-theoretic algorithmic idea that we’re calling Regularised Nash Dynamics (R-NaD). Working at an unparalleled scale, R-NaD steers DeepNash’s learning behaviour towards what’s known as a Nash equilibrium (dive into the technical details in our paper).
Game-playing behaviour that results in a Nash equilibrium is unexploitable over time. If a person or machine played perfectly unexploitable Stratego, the worst win rate they could achieve would be 50{29fe85292aceb8cf4c6c5bf484e3bcf0e26120073821381a5855b08e43d3ac09}, and only if facing a similarly perfect opponent.
In matches against the best Stratego bots – including several winners of the Computer Stratego World Championship – DeepNash’s win rate topped 97{29fe85292aceb8cf4c6c5bf484e3bcf0e26120073821381a5855b08e43d3ac09}, and was frequently 100{29fe85292aceb8cf4c6c5bf484e3bcf0e26120073821381a5855b08e43d3ac09}. Against the top expert human players on the Gravon games platform, DeepNash achieved a win rate of 84{29fe85292aceb8cf4c6c5bf484e3bcf0e26120073821381a5855b08e43d3ac09}, earning it an all-time top-three ranking.
Expect the unexpected
To achieve these results, DeepNash demonstrated some remarkable behaviours both during its initial piece-deployment phase and in the gameplay phase. To become hard to exploit, DeepNash developed an unpredictable strategy. This means creating initial deployments varied enough to prevent its opponent spotting patterns over a series of games. And during the game phase, DeepNash randomises between seemingly equivalent actions to prevent exploitable tendencies.
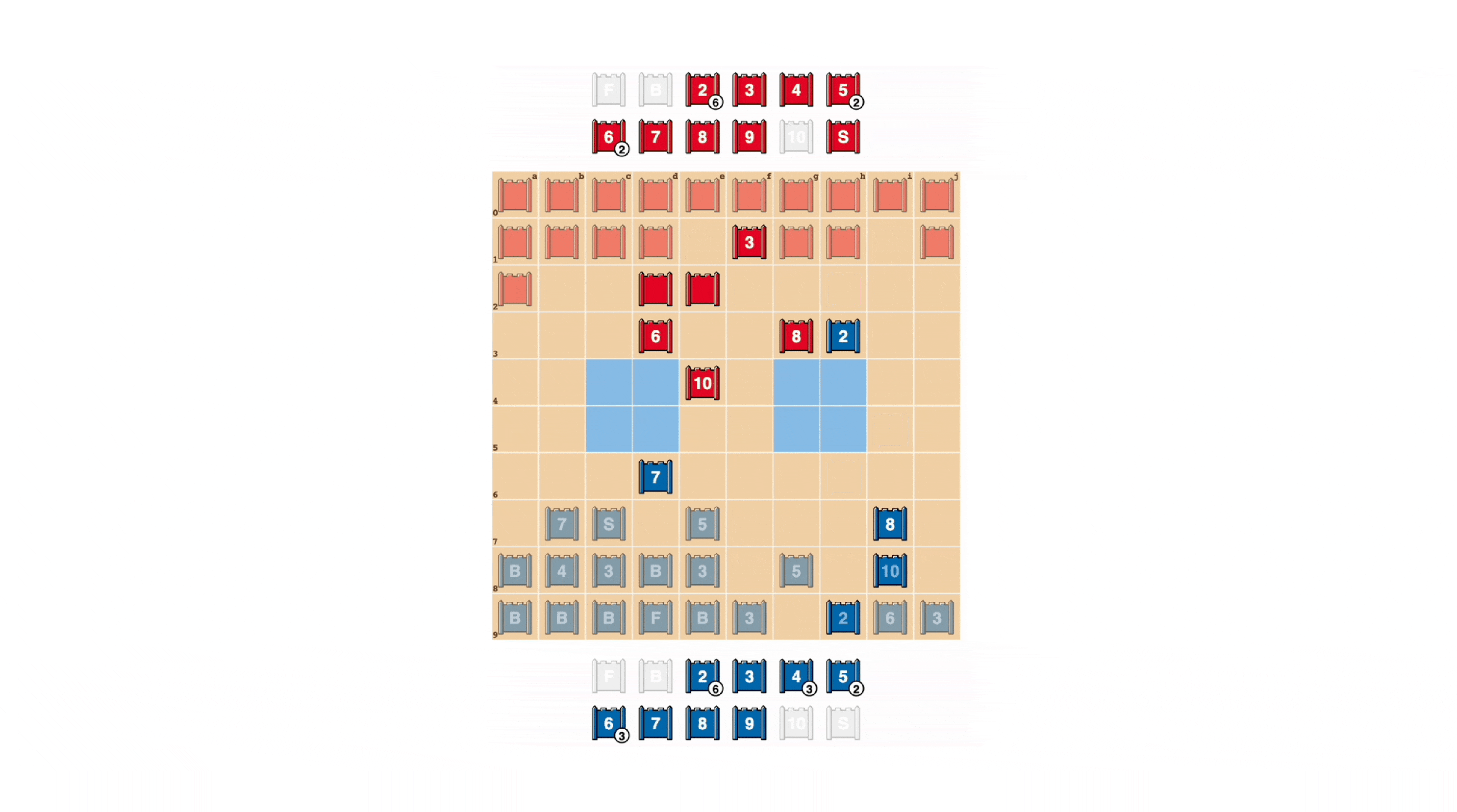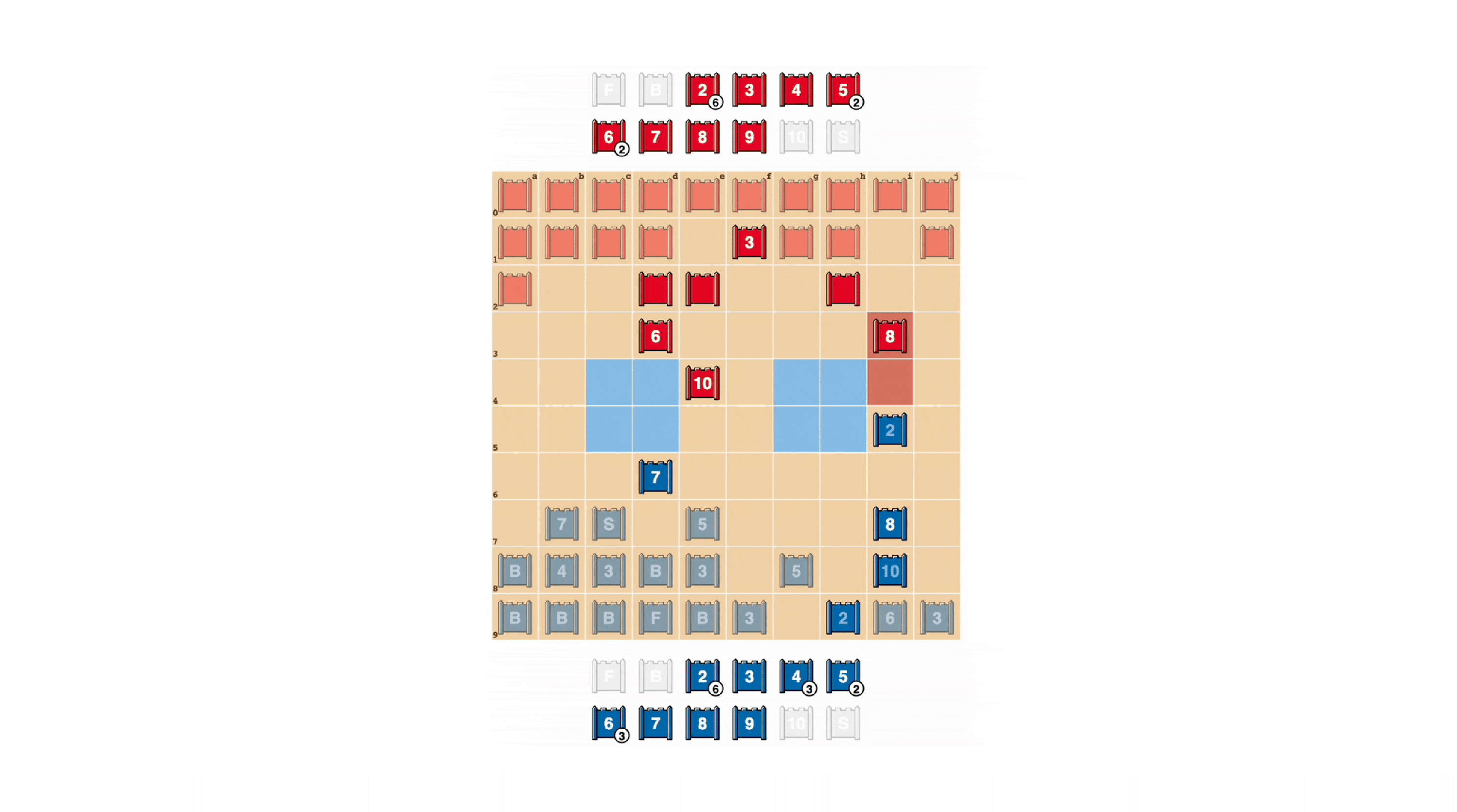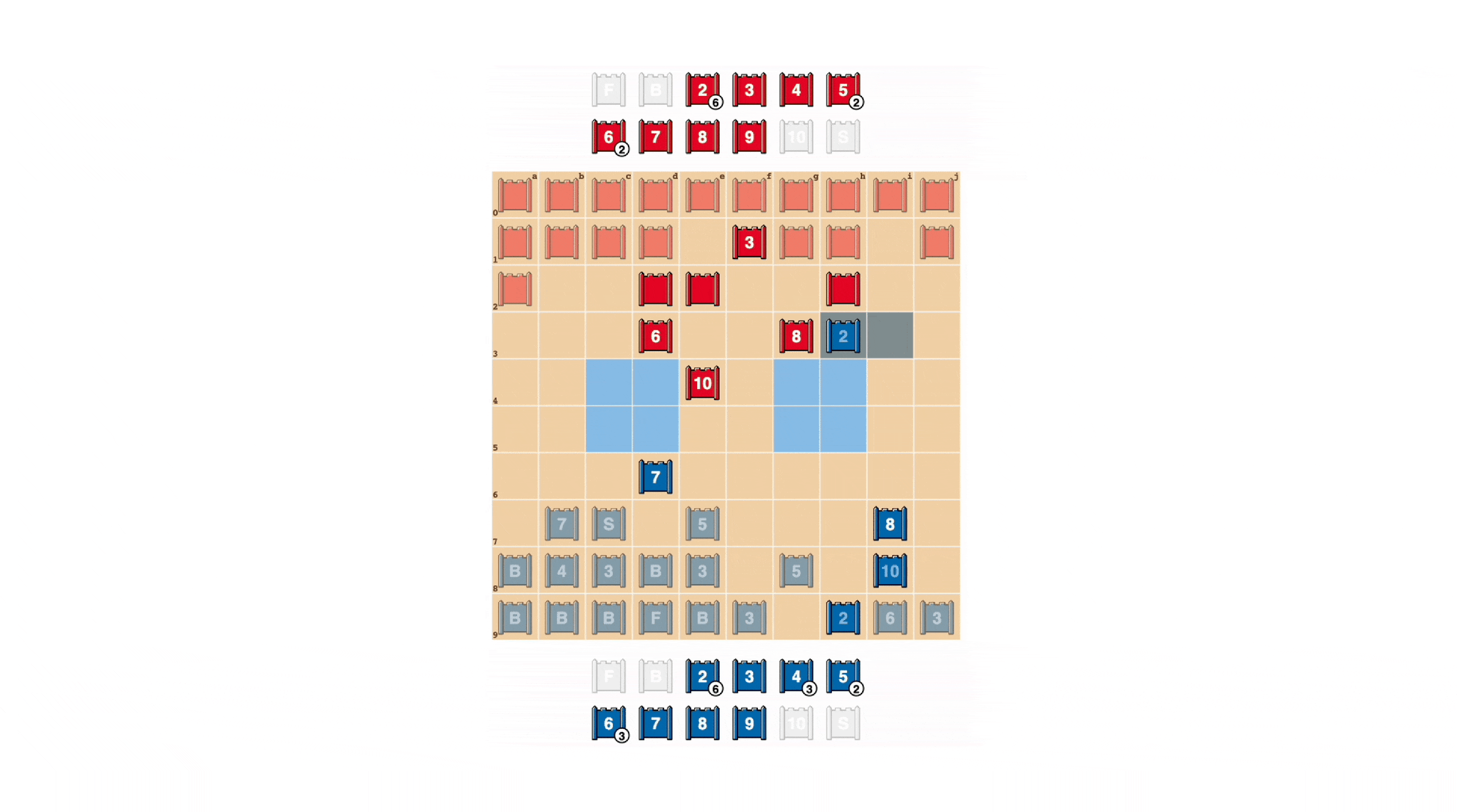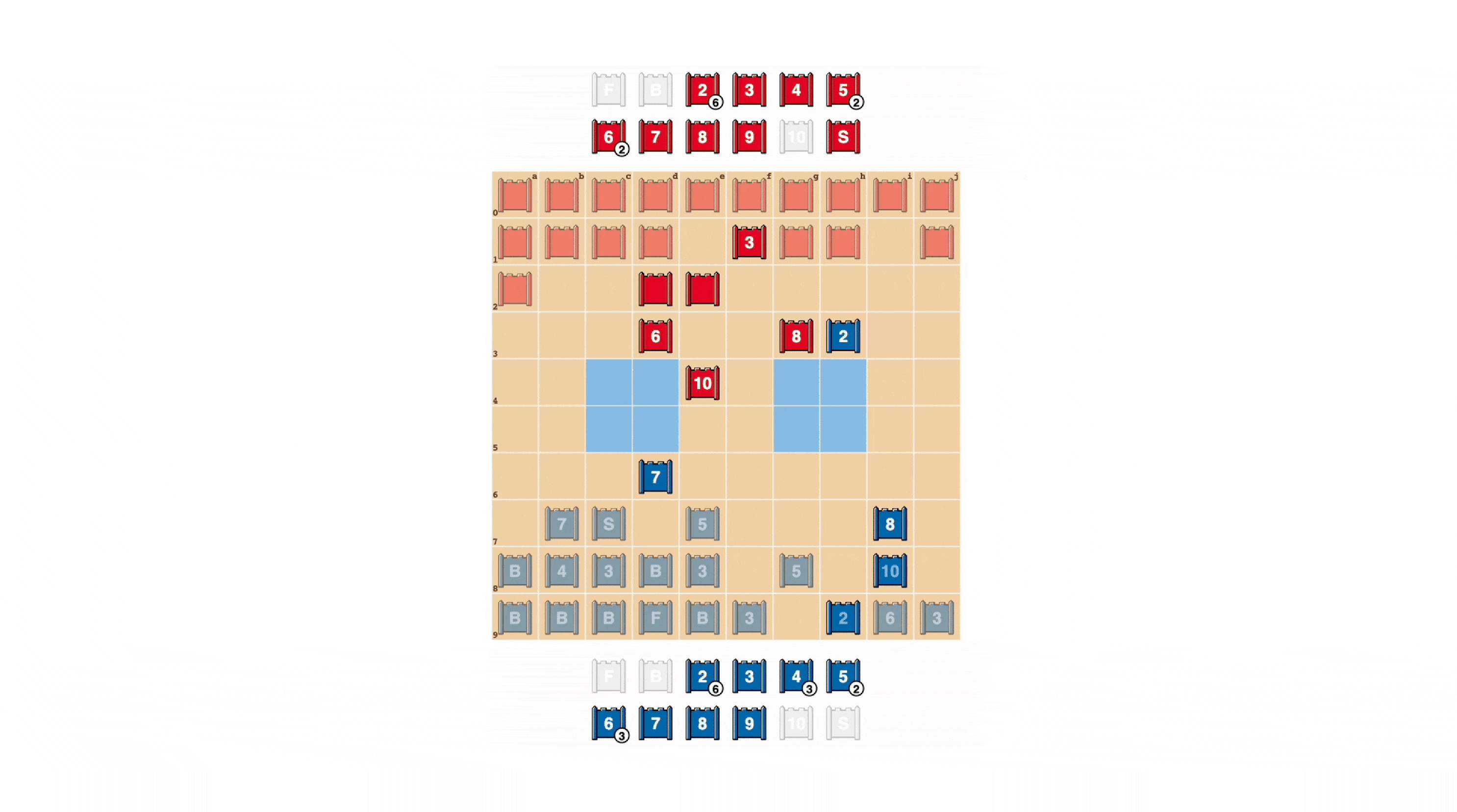
Stratego players strive to be unpredictable, so there’s value in keeping information hidden. DeepNash demonstrates how it values information in quite striking ways. In the example below, against a human player, DeepNash (blue) sacrificed, among other pieces, a 7 (Major) and an 8 (Colonel) early in the game and as a result was able to locate the opponent’s 10 (Marshal), 9 (General), an 8 and two 7’s.
These efforts left DeepNash at a significant material disadvantage; it lost a 7 and an 8 while its human opponent preserved all their pieces ranked 7 and above. Nevertheless, having solid intel on its opponent’s top brass, DeepNash evaluated its winning chances at 70{29fe85292aceb8cf4c6c5bf484e3bcf0e26120073821381a5855b08e43d3ac09} – and it won.
The art of the bluff
As in poker, a good Stratego player must sometimes represent strength, even when weak. DeepNash learned a variety of such bluffing tactics. In the example below, DeepNash uses a 2 (a weak Scout, unknown to its opponent) as if it were a high-ranking piece, pursuing its opponent’s known 8. The human opponent decides the pursuer is most likely a 10, and so attempts to lure it into an ambush by their Spy. This tactic by DeepNash, risking only a minor piece, succeeds in flushing out and eliminating its opponent’s Spy, a critical piece.
See more by watching these four videos of full-length games played by DeepNash against (anonymised) human experts: Game 1, Game 2, Game 3, Game 4.
“The level of play of DeepNash surprised me. I had never heard of an artificial Stratego player that came close to the level needed to win a match against an experienced human player. But after playing against DeepNash myself, I wasn’t surprised by the top-3 ranking it later achieved on the Gravon platform. I expect it would do very well if allowed to participate in the human World Championships.”
– Vincent de Boer, paper co-author and former Stratego World Champion
Future directions
While we developed DeepNash for the highly defined world of Stratego, our novel R-NaD method can be directly applied to other two-player zero-sum games of both perfect or imperfect information. R-NaD has the potential to generalise far beyond two-player gaming settings to address large-scale real-world problems, which are often characterised by imperfect information and astronomical state spaces.
We also hope R-NaD can help unlock new applications of AI in domains that feature a large number of human or AI participants with different goals that might not have information about the intention of others or what’s occurring in their environment, such as in the large-scale optimisation of traffic management to reduce driver journey times and the associated vehicle emissions.
In creating a generalisable AI system that’s robust in the face of uncertainty, we hope to bring the problem-solving capabilities of AI further into our inherently unpredictable world.
Learn more about DeepNash by reading our paper in Science.
For researchers interested in giving R-NaD a try or working with our newly proposed method, we’ve open-sourced our code.