")


The need for efficient and trustworthy techniques to assess the performance of Large Language Models (LLMs) is increasing as these models are incorporated into more and more domains. When evaluating how effectively LLMs operate in dynamic, real-world interactions, traditional assessment standards are frequently used on static datasets, which present serious issues.
Since the questions and responses in these static datasets are usually unchanging, it is challenging to predict how a model would respond to changing user discussions. A lot of these benchmarks call for the model to use particular prior knowledge, which might make it more difficult to evaluate a model’s capacity for logical reasoning. This reliance on pre-established knowledge restricts assessing a model’s capacity for reasoning and inference independent of stored data.
Other methods of evaluating LLMs include dynamic interactions, like manual evaluations by human assessors or the use of high-performing models as a benchmark. These approaches have disadvantages of their own, even though they may provide a more adaptable evaluation environment. Strong models may have a specific style or methodology that affects the evaluation process; therefore, using them as benchmarks can introduce biases. Manual evaluation frequently requires a significant amount of time and money, making it unfeasible for large-scale applications. These limitations draw attention to the need for a substitute that balances cost-effectiveness, evaluation fairness, and the dynamic character of real-world interactions.
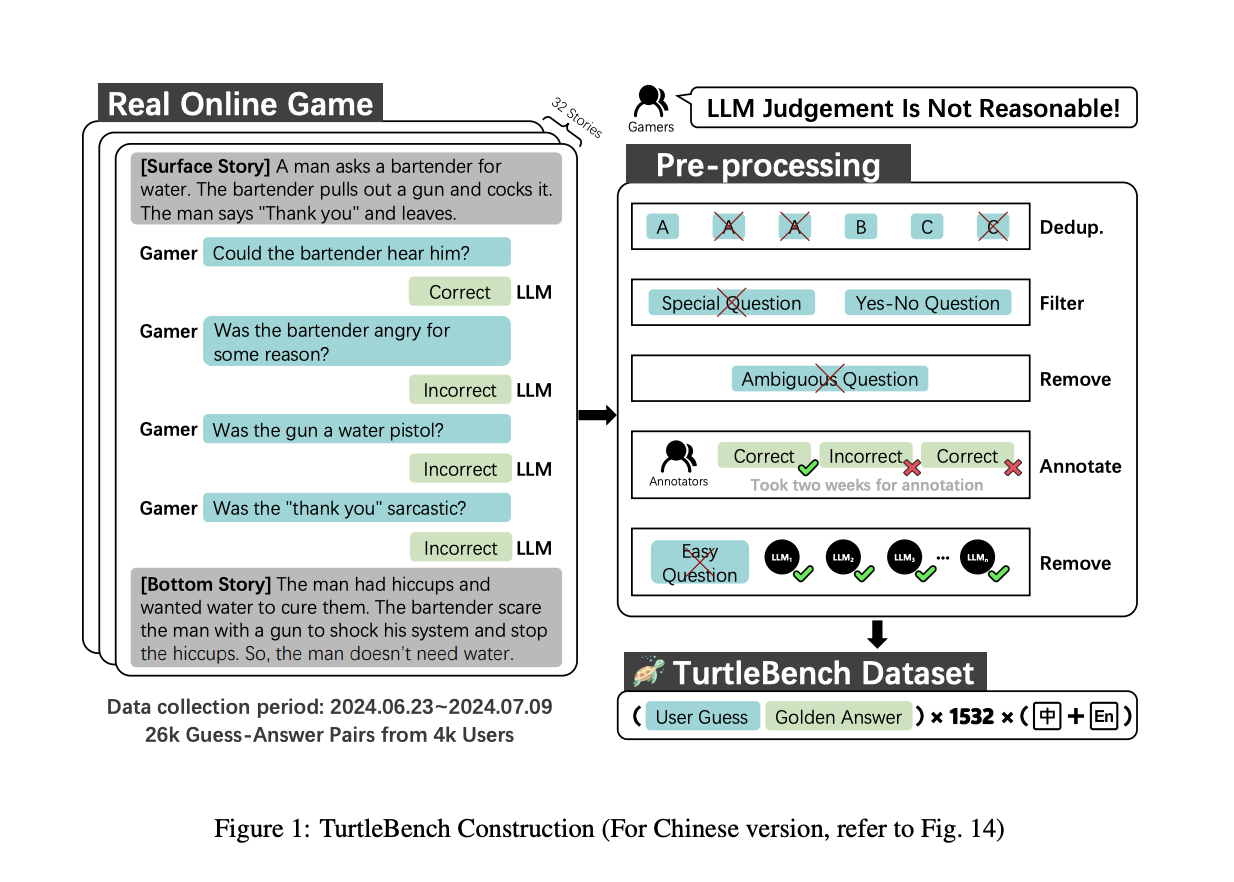
In order to overcome these issues, a team of researchers from China has introduced TurtleBench, a unique evaluation system. TurtleBench employs a strategy by gathering actual user interactions via the Turtle Soup Puzzle1, a specially designed web platform. Users of this site can participate in reasoning exercises where they must guess based on predetermined circumstances. A more dynamic evaluation dataset is then created using the data points gathered from the users’ predictions. Models cheating by memorizing fixed datasets are less likely to use this approach because the data changes in response to real user interactions. This configuration provides a more accurate representation of a model’s practical capabilities, which also guarantees that the assessments are more closely linked with the reasoning requirements of actual users.
The 1,532 user guesses in the TurtleBench dataset are accompanied by annotations indicating the accuracy or inaccuracy of each guess. This makes it possible to examine in-depth how successfully LLMs do reasoning tasks. TurtleBench has carried out a thorough analysis of nine top LLMs using this dataset. The team has shared that OpenAI o1 series models did not win these tests.
According to one theory that came out of this study, the OpenAI o1 models’ reasoning abilities depend on comparatively basic Chain-of-Thought (CoT) strategies. CoT is a technique that can assist models become more accurate and clear by generating intermediate steps of reasoning before reaching a final conclusion. On the other hand, it appears that the o1 models’ CoT processes might be too simple or surface-level to do well on challenging reasoning tasks. According to another theory, lengthening CoT processes can enhance a model’s ability to reason, but it may also add additional noise or unrelated or distracting information, which could cause the reasoning process to get confused.
The TurtleBench evaluation’s dynamic and user-driven features assist in guaranteeing that the benchmarks stay applicable and change to meet the changing requirements of practical applications.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.