Red teaming plays a pivotal role in evaluating the risks associated with AI models and systems. It uncovers novel threats, identifies gaps in current safety measures, and strengthens quantitative safety metrics. By fostering the development of new safety standards, it bolsters public trust and enhances the legitimacy of AI risk assessments.
This paper details OpenAI’s approach to external red teaming, highlighting its role in evaluating and mitigating risks in advanced AI models and systems. By collaborating with domain experts, OpenAI’s red teaming efforts provide valuable insights into model capabilities and vulnerabilities. While the focus is on OpenAI’s practices, the outlined principles offer broader relevance, guiding other organizations and stakeholders in integrating human red teaming into their AI risk assessment and evaluation frameworks.
Red teaming has become a cornerstone of safety practices in AI development, with OpenAI implementing external red teaming since the deployment of DALL-E 2 in 2022. This practice involves structured testing to uncover AI systems’ vulnerabilities, harmful outputs, and risks. It has informed safety measures across AI labs and aligns with policy initiatives like the 2023 Executive Order on AI safety, which emphasizes red teaming as a critical evaluation method. Governments and companies worldwide increasingly incorporate these practices into their AI risk assessments.
External red teaming offers significant value by addressing critical aspects of AI risk assessment and safety. It uncovers novel risks, such as unintended behaviors arising from advancements in model capabilities, like GPT-4o emulating a user’s voice. It also stress-tests existing defenses, identifying vulnerabilities, such as visual synonyms bypassing safeguards in DALL-E systems. By incorporating domain expertise, red teaming enhances assessments with specialized knowledge, as seen in evaluating scientific applications of AI models. In addition, it provides independent evaluations, fostering trust by mitigating biases and ensuring objective insights into potential risks and system behaviors.
Red teaming practices vary widely, with emerging methods tailored to the evolving complexity of AI systems. Model developers may disclose the scope, assumptions, and testing criteria, including details about model iterations, testing categories, and notable insights. Manual methods involve human experts crafting adversarial prompts to assess risks, while automated techniques use AI to generate prompts and evaluate outputs systematically. Mixed methods combine these approaches, creating feedback loops where manual testing seeds data for automated scaling. OpenAI has implemented these methods in System Cards, refining red teaming for frontier model evaluations.
Designing an effective red teaming campaign involves strategic decisions and structured methodologies to assess AI risks and impacts. Key steps include defining the cohort of red teamers based on testing goals and relevant domains and considering questions about the model and applicable threat models. Developers must determine the model versions accessible to red teamers and provide clear interfaces, instructions, and documentation. The final stage involves synthesizing data gathered from testing and creating comprehensive evaluations. These steps ensure thorough, goal-oriented risk assessments for AI systems.
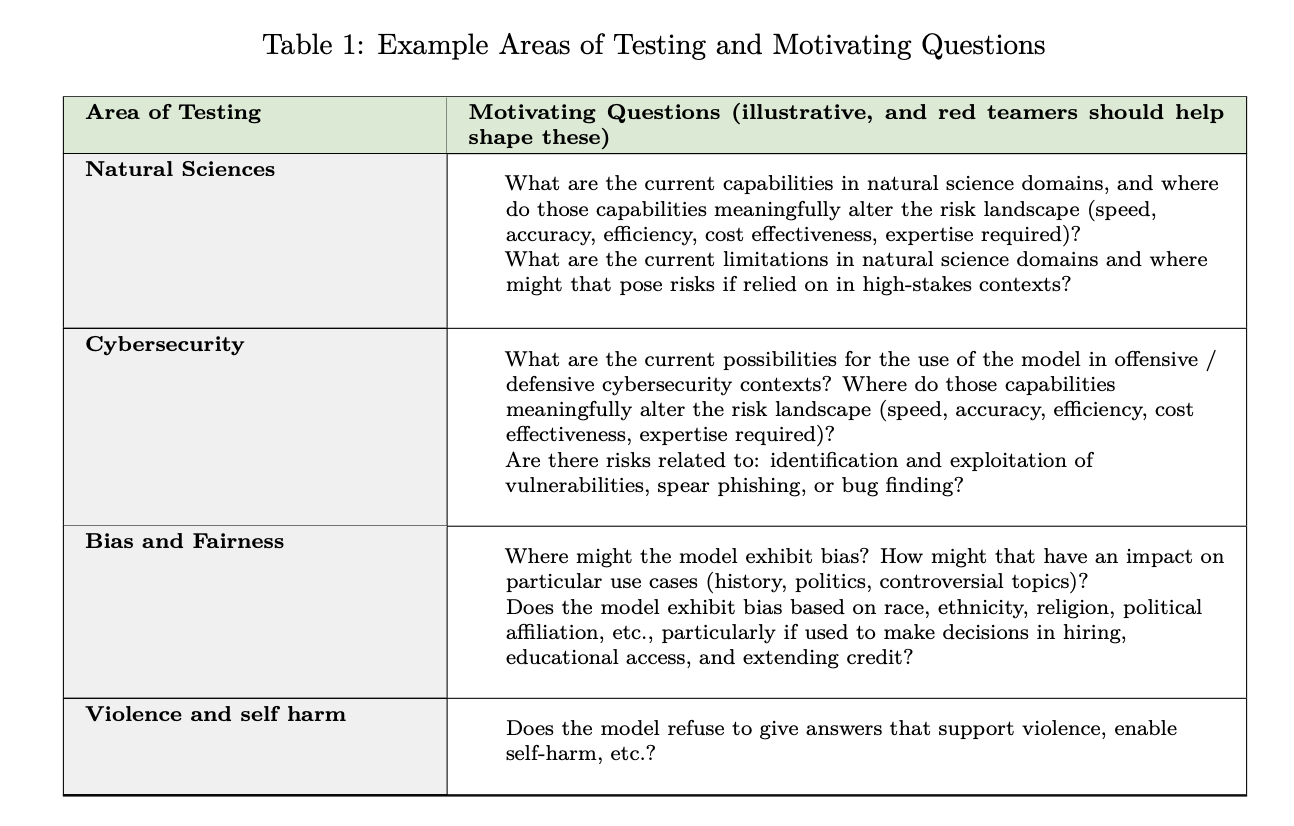
Comprehensive red teaming for AI systems requires testing across diverse topics, reflecting the varied use cases and risks associated with these technologies. Threat modeling guides domain prioritization, focusing on areas like anticipated capabilities, previous policy issues, contextual factors, and expected applications. Each testing area is anchored by hypotheses addressing risks, their targets, and their sources, ensuring a structured approach. While internal teams initially prioritize testing based on early evaluations and development insights, external red teamers contribute valuable perspectives, refining and expanding the scope of testing through their expertise and findings.
The transition from human red teaming to automated evaluations is essential for scalable and consistent AI safety assessments. After red teaming campaigns, teams analyze whether identified examples align with existing policies or necessitate new guidelines. Insights from campaigns extend beyond explicit risks, highlighting issues like disparate performance, quality concerns, and user experience preferences. For instance, GPT-4o red teaming uncovered unauthorized voice generation behaviors, driving the development of robust mitigations and evaluations. Data generated by human red teamers also seeds automated evaluations, enabling quicker, cost-effective assessments by using classifiers and benchmarks to test desirable behaviors and identify vulnerabilities.
While red teaming is a valuable tool for AI risk assessment, it has several limitations and risks. One challenge is the relevance of findings to evolving models, as updates may render previous assessments less applicable. Red teaming is resource-intensive, making it inaccessible for smaller organizations, and exposing participants to harmful content can pose psychological risks. Also, the process can create information hazards, potentially aiding misuse if safeguards are inadequate. Issues of fairness arise when red teamers gain early access to models, and growing model sophistication raises the bar for human expertise needed in risk evaluation.
This paper highlights the role of external red teaming in AI risk assessment, emphasizing its value in strengthening safety evaluations over time. As AI systems rapidly evolve, understanding user experiences, potential misuse, and real-world factors like cultural nuances becomes crucial. While no single process can address all concerns, red teaming, particularly when involving diverse domain experts, offers a proactive mechanism for risk discovery and evaluation development. However, further work is needed to integrate public perspectives and establish accountability measures. Red teaming, alongside other safety practices, is essential for creating actionable AI risk assessments.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.