")







Recent advances in autoregressive language models have brought about an amazing transformation in the field of Natural Language Processing (NLP). These models, such as GPT and others, have exhibited excellent performance in text creation tasks, including question-answering and summarization. However, their high inference latency poses a significant barrier to their general application, particularly in highly deep models with hundreds of billions of parameters. This lag results from their nature because autoregressive models generate text one token at a time in a series. This leads to a significant increase in computing demand, which restricts the models’ ability to be deployed in real time.
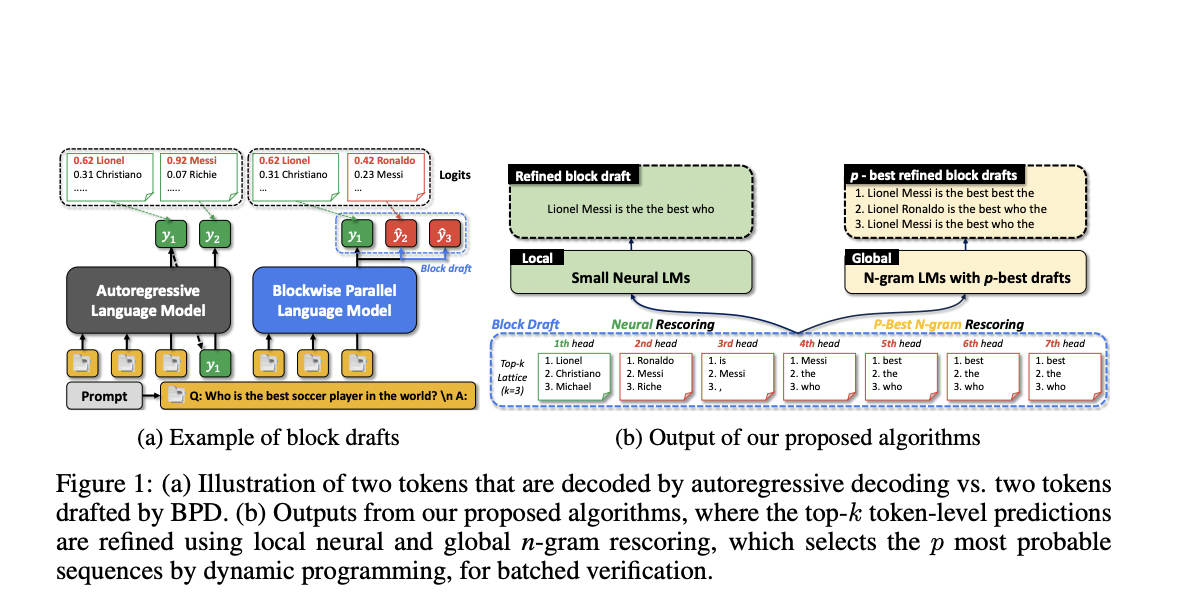
To address this problem, a team of researchers from KAIST and Google has developed Blockwise Parallel Decoding (BPD), a method designed to speed up the inference of these models. Known as block drafts, BPD permits the simultaneous prediction of several future tokens, in contrast to typical autoregressive methods. Multiple prediction heads construct these block drafts in parallel, and the autoregressive model then selects and conditionally accepts the best-fit tokens.
Because several tokens are presented simultaneously, this technique greatly accelerates inference speed by decreasing the amount of time spent waiting for sequential token predictions. But BPD comes with its own set of difficulties, especially in making sure the block drafts are precise and well-organized enough for the model to accept them.
The team has shared two key ways by which the effectiveness of the block drafts has been advanced. The token distributions generated by the several prediction heads in BPD have been first examined. The goal of this analysis is to better understand how the model simultaneously generates several tokens and how to optimize these predictions for increased fluency and accuracy. Through the analysis of these token distributions, trends or irregularities that could impair block draft performance can be spotted.
Second, using this research, the study creates algorithms that improve the block drafts. The team has specifically suggested employing neural language models and n-gram models to enhance the block drafts’ quality prior to the autoregressive model’s verification. While neural language models provide more sophisticated context awareness, which helps to make block drafts more in line with the model’s expectations, n-gram models help guarantee local consistency in token predictions.
The study’s testing yielded encouraging results, with improved block drafts increasing block efficiency, which is a measure of how many tokens from the block draft are eventually accepted by the autoregressive model by 5-21%. These gains were shown on several different datasets, indicating the method’s resilience.
The team has summarized their primary contributions as follows.
- The study looks into how prediction heads behave in blockwise parallel language models (BPD), finding evidence of falling confidence in predictions for later tokens and significant consecutive token repetition (20% to 75%). This draws attention to poor block draft quality.
- The team has proposed the notion of Oracle top-k block efficiency. They demonstrate that block efficiency can be greatly increased by lowering repetition and uncertainty and taking into account the top-k most likely tokens for each head.
- Two algorithms have been introduced – Global rescoring using n-gram models, which efficiently rescore many candidate drafts, and Local rescoring using neural LMs, which refines block drafts for fluency and coherence. These techniques maximize resource utilization while increasing block efficiency by up to 21.3%.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Want to get in front of 1 Million+ AI Readers? Work with us here
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.