Large Language Models (LLMs) have gained significant attention in data management, with applications spanning data integration, database tuning, query optimization, and data cleaning. However, analyzing unstructured data, especially complex documents, remains challenging in data processing. Recent declarative frameworks designed for LLM-based unstructured data processing focus more on reducing costs than enhancing accuracy. This creates problems for complex tasks and data, where LLM outputs often lack precision in user-defined operations, even with refined prompts. For example, LLMs may have difficulty identifying every occurrence of specific clauses, like force majeure or indemnification, in lengthy legal documents, making it necessary to decompose both data and tasks.
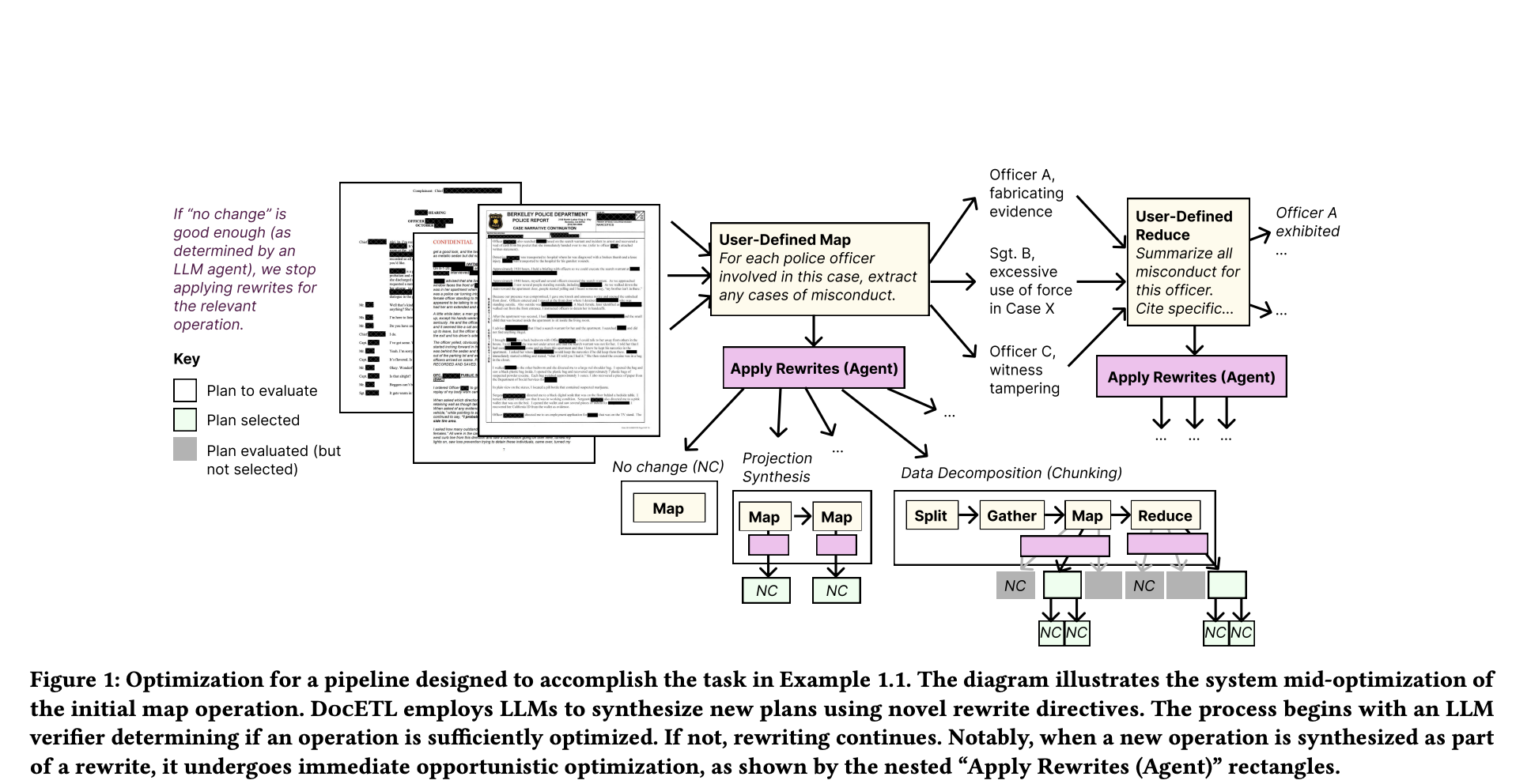
For Police Misconduct Identification (PMI), journalists at the Investigative Reporting Program at Berkeley want to analyze a large corpus of police records obtained through records requests to uncover patterns of officer misconduct and potential procedural violations. PMI poses the challenges of analyzing complex document sets, such as police records, to identify officer misconduct patterns. This task involves processing heterogeneous documents to extract and summarize key information, compile data across multiple documents, and create detailed conduct summaries. Current approaches handle these tasks as single-step map operations, with one LLM call per document. However, this method often lacks accuracy due to issues like document length surpassing LLM context limits, missing critical details, or including irrelevant information.
Researchers from UC Berkeley and Columbia University have proposed DocETL, an innovative system designed to optimize complex document processing pipelines while addressing the limitations of LLMs. This method provides a declarative interface for users to define processing pipelines and uses an agent-based framework for automatic optimization. Key features of DocETL include logical rewriting of pipelines tailored for LLM-based tasks, an agent-guided plan evaluation mechanism that creates and manages task-specific validation prompts, and an optimization algorithm that efficiently identifies promising plans within LLM-based time constraints. Moreover, DocETL shows major improvements in output quality across various unstructured document analysis tasks.
DocETL is evaluated on PMI tasks using a dataset of 227 documents from California police departments. The dataset presented significant challenges, including lengthy documents averaging 12,500 tokens, with some exceeding the 128,000 token context window limit. The task involves generating detailed misconduct summaries for each officer, including names, misconduct types, and comprehensive summaries. The initial pipeline in DocETL consists of a map operation to extract officers exhibiting misconduct, an unnest operation to flatten the list, and a reduced operation to summarize misconduct across documents. The system evaluated multiple pipeline variants using GPT-4o-mini, demonstrating DocETL’s ability to optimize complex document processing tasks. The pipelines are DocETLS, DocETLT, and DocETLO.
Human evaluation is conducted on a subset of the data using GPT-4o-mini as a judge across 1,500 outputs to validate the LLM’s judgments, revealing high agreement (92-97%) between the LLM judge and human assessor. The results show that DocETL𝑂 is 1.34 times more accurate than the baseline. DocETLS and DocETLT pipelines performed similarly, with DDocETLS often omitting dates and locations. The evaluation highlights the complexity of evaluating LLM-based pipelines and the importance of task-specific optimization and evaluation in LLM-powered document analysis. DocETL’s custom validation agents are crucial to finding the relative strengths of each plan and highlighting the system’s effectiveness in handling complex document processing tasks.
In conclusion, researchers introduced DocETL, a declarative system for optimizing complex document processing tasks using LLMs, addressing critical limitations in existing LLM-powered data processing frameworks. It utilizes innovative rewrite directives, an agent-based framework for plan rewriting and evaluation, and an opportunistic optimization strategy to tackle the specific challenges of complex document processing. Moreover, DocETL can produce outputs of 1.34 to 4.6 times higher quality than hand-engineered baselines. As LLM technology continues to evolve and new challenges in document processing arise, DocETL’s flexible architecture offers a strong platform for future research and applications in this fast-growing field.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.